I only recently found out that Chrome has started shipping experimental support for VP9 and AV1 simulcast. If you’ve visited this blog before, you know what simulcast is already (if you don’t, make sure you read this post first!) and you may recall we’ve talked, on separate occasions, about both codecs, but typically with respect to their SVC capabilities, namely in the post on VP9/SVC support in Janus, and the one on our AV1/SVC experiments.
Of course, I was very much interested in checking out how I could extend the simulcast support we have in Janus to VP9 and AV1 as well: as a nice side effect, this helped me fix our broken support for AV1/SVC as well, which means I’ll actually cover both in this post.
Why VP9/AV1 simulcast? What’s wrong with SVC?
While it’s clear that investing on SVC is and remains a good idea, it’s also clear that simulcast is still very much more widespread in existing deployments, and a preferred choice of many production environments. In fact, while Chrome does have experimental support for SVC, not all other browsers do: as a result, not many companies have started investigating it yet, leading the vast majority of them to indeed stick to simulcast instead.
That said, for many years it’s only been available for VP8 and (partly, without temporal layers) H.264, which forced people interested in simulcast to “settle down” with codecs that may not provide as good as an experience as more recent and efficient ones. For this reason, news about simulcast now being available for VP9 and AV1 as well are indeed great news, since they help pave the way towards a time where SVC will be more usable too.
Besides, one thing not many people are aware of is that what we usually call “simulcast”, actually also has a sprinkle of SVC in there too. In fact, when you enable VP8 simulcast in your client, you not only start sending multiple streams at different qualities/bitrates, but also enable the so-called “temporal layers”, which allow you to selectively cut down on the framerate of selected substreams to further reduce the bitrate when needed. Temporal layers are indeed a feature of SVC, not simulcast per se, since they represent the concent of multiple streams actually encoded in one (where you can drop selected packets and still get something meaningful).
As we’ll see in a second, temporal layers can be enabled for VP9/AV1 simulcast too, and in a configurable way.
Enabling VP9/AV1 simulcast
As explained in the PSA, in order to test this new support for VP9 and AV1 simulcast you have to configure the simulcast envelope in a specific way, when adding the transceiver. Specifically, you have to specify both a scalabilityMode (which as we’ll see will impact the previously mentioned temporal layers) and scaleResolutionDownBy (to trigger the separate streams part of the simulcast context). This is indeed necessary because the same envelope can also be used to setup an SVC context instead, and since both codecs do have native support for SVC, being explicit about what you want to achieve is a required step, at least in this initial integration.
We introduced the concept of the simulcast envelope in a previous post, so an example of a way to enable simulcast for VP9 and AV1 (assuming either one is the codec that will end up being used) is the following:
transceiver = pc.addTransceiver(nt, {
direction: 'sendrecv',
streams: stream,
sendEncodings: [
{ rid: 'h', active: true, scalabilityMode: 'L1T2', maxBitrate: 1500000 },
{ rid: 'm', active: true, scalabilityMode: 'L1T2', maxBitrate: 400000, scaleResolutionDownBy: 2 },
{ rid: 'l', active: true, scalabilityMode: 'L1T2', maxBitrate: 100000, scaleResolutionDownBy: 4 }
]
});In this example, we’re creating a simulcast envelope with three different substreams:
- one, identified by rid
h, with the highest resolution available, and with a bitrate of about 1.5mbps; - a second one, identified by rid
m, of half the resolution, and a lower bitrate (about 400kbps); - a third one, identified by rid
l, with a quarter of the target resolution, and the lowest bitrate of them all (~100kbps).
For all of them, though, we also provided a scalabilityMode property with value L1T2: this means that, for each of the substreams we’re adding, we also want to enable 2 temporal layers, which is in line with what usually happens by default when you enable VP8 simulcast in browsers.
On a recent version of Chrome (the PSA mentions M113, I used Chrome v115.0.5750.0 in my tests) that’s enough to enable them, so let’s check what, if anything, had to be changed in Janus to get them working.
Updating Janus to accept VP9/AV1 simulcast
Janus has been supporting simulcast for a very long time. That said, considering that as anticipated browsers historically only supported it for VP8 and H.264, support in Janus ended up being obviously more biased (or should we say tailored?) towards those codecs when detecting simulcast support in incoming calls. This bias is actually something that mostly happens in plugins. In fact, while it’s the Janus core that’s responsible for terminating the WebRTC negotiation and exchange of media packets (which includes demultiplexing incoming simulcast traffic), it’s actually plugins that decide if/how features should be used, which includes simulcast.
As such, I decided to check what change would be needed to get Janus (and its plugins) to properly handle VP9 and AV1 as options as well, when it comes to simulcast support. It turns out, we didn’t need to change much, actually: if you want to check what exactly needed to be extended, you can refer to the pull request implementing this feature that, at the time of writing, hasn’t been merged yet.
As it often happens, I decided to start from the EchoTest plugin as a testbed for this new functionality: in fact, as a plugin that simply mirrors back whatever it is sent (and, for simulcast or SVC, acting as an SFU in the process), it’s definitely the easiest to prototype new functionality in. To get something working there, the first thing we needed to get rid of were any hardcoded constraints mentioning VP8 or H.264 when talking of simulcast support, which was a simple enough change. The next step was ensuring that the core utils processing simulcast traffic (which happens in a function called janus_rtp_simulcasting_context_process_rtp) had that constraint removed as well: in that case, the process was easy too, since we just had to let that function be aware of how to detect VP9 and AV1 keyframes (which is needed when you have to switch substreams).
This first very barebone changes were already enough to get something working. In fact, modifying the janus.js library to configure the simulcast envelope as described above, and then launching the EchoTest demo to force simulcast (simulcast=true in the query string) and the right codec (e.g., vcodec=vp9), I could verify from webrtc-internals that simulcast had been properly enabled:

After that, I could also verify that VP9 simulcast was indeed working, as buttons appeared in the demo UI as expected, and clicking them to trigger substream changes programmatically worked as well. Success!
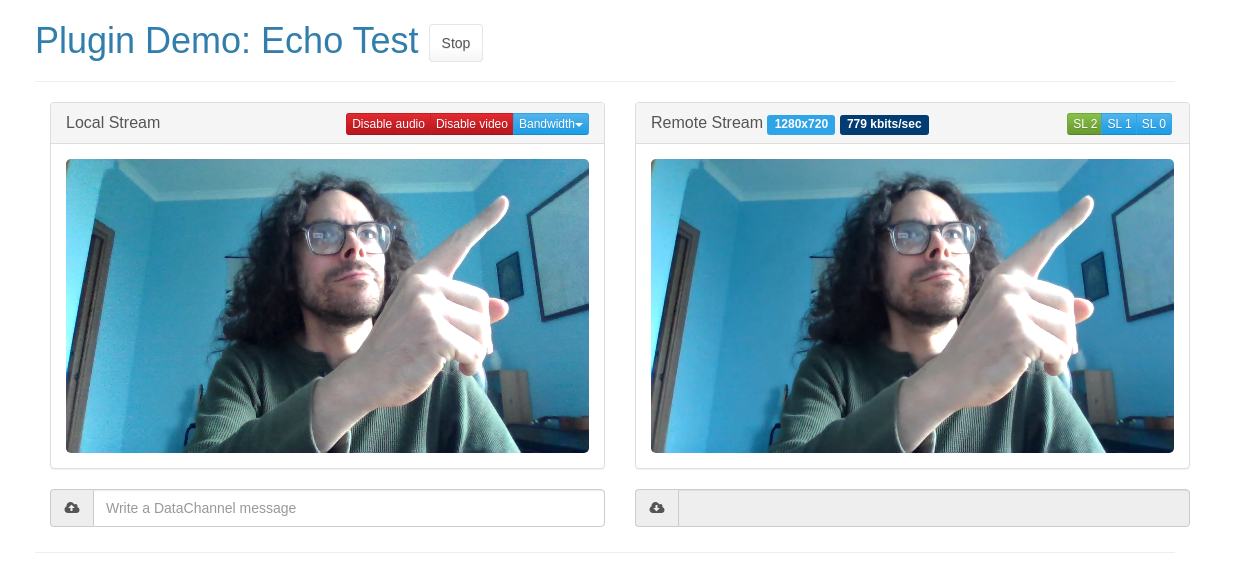
Even though, something was still amiss, and there’s something you may be wondering about too by looking at the picture above…
Where are temporal layers?
Good question! Where are they? We know they’re being sent, because we’ve used L1T2 as our scalabilityMode, and we’ve seen in webrtc-internals that it has been recognized and used. For some reason, though, they’re not being processed, which means all temporal layers are always sent to the receiver (which is as if they were never enabled at all).
This was actually expected, and something I was aware of, and for a simple reason. As we discussed previously, for simulcast temporal layers are only enabled for VP8, and not for H.264: as a consequence, our code for detecting (and possibly discarding) temporal layers was very much VP8-specific. More precisely, in our code we inspect the beginning of VP8 packets to do that, since information on temporal layers is actually part of the so-called VP8 Payload Descriptor. This codec-specific behaviour made it obvious that, for other codecs like VP9 and AV1 that may include temporal layers too, a different approach would be needed.
The easiest to start from was VP9, for a simple reason: I already had code in Janus for detecting VP9 temporal layers, since we already supported VP9 SVC (and temporal layers are SVC, remember?). As such, I modified the code looking for temporal layers so that it would use that when using VP9, and voilà, temporal layers magically appeared, and worked in a simulcast context too!
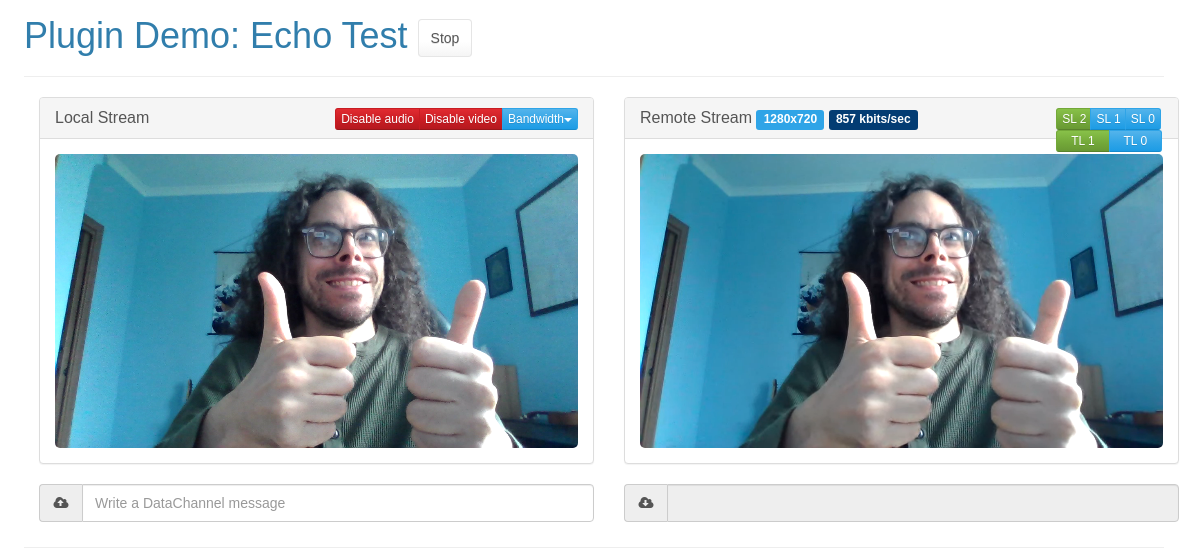
For AV1, though, it was an entirely different matter. Inspecting the payload sounded like a bad idea, so a different approach would be needed instead. I wasn’t sure, though, if there was a different place Chrome would put info on those temporal layers: there are a couple of RTP extensions that seemed relevant, but with no guarantee on whether they’d actually contain the info we needed.
Specifically, even though Chrome doesn’t offer (or negotiate) them by default, there’s a couple that are available:
- the Generic Frame Descriptor extension, which is non-standard, and
- the Dependency Descriptor extension, which was originally conceived for AV1/SVC usage.
I was familiar with the latter already, since I had worked (fought?) with it already, as documented in my AV1/SVC experiments post. I wasn’t really eager to get back to it, since I remembered the scars, but Philipp Hancke suggested it should actually contain the right info, so I decided to roll up my sleeves and get back at it again.
It turns out that, forcing Chrome to negotiate the extension via some ugly munging, the extension did indeed contain the right information (since, again, temporal layers are SVC, and that’s what the extension is for). Besides, making it usable in Janus was also quite straightforward! In fact, I had done the lion’s share of the work already at the time, meaning Janus already comes with a fully functional Dependency Descriptor extension parser: this parser did provide information on temporal layers too, which meant it was trivial to use that information for AV1 simulcast as well.
In order to get this working, as anticipated I had to first munge the SDP offer to negotiate the extension. In the EchoTest demo, this can be done by using the customizeSdp callback when doing a createOffer, so I just bluntly did a replacement in the SDP string:
customizeSdp: function(jsep) {
[..]
jsep.sdp = jsep.sdp.replace("a=extmap:11 urn:ietf:params:rtp-hdrext:sdes:repaired-rtp-stream-id",
"a=extmap:11 urn:ietf:params:rtp-hdrext:sdes:repaired-rtp-stream-id\r\na=extmap:9 https://aomediacodec.github.io/av1-rtp-spec/#dependency-descriptor-rtp-header-extension");
},Notice that this a horrible way to enable the extension: I’m just hardcoding 9 as the ID for the Dependency Descriptor extension, and assuming that the SDP does contain a repaired-rid extmap line with ID 11 to piggyback the replacement, while you’d want something more reliable in a production environment. That said, it’s good enough for an ugly prototype test, as if you check webrtc-internals you’ll see the extension be properly negotiated:

After that, telling the EchoTest demo to enable simulcast and forcing AV1 (vcodec=av1) is enough to get it started, and thanks to the updated support in Janus this got indeed temporal layers to work as expected:
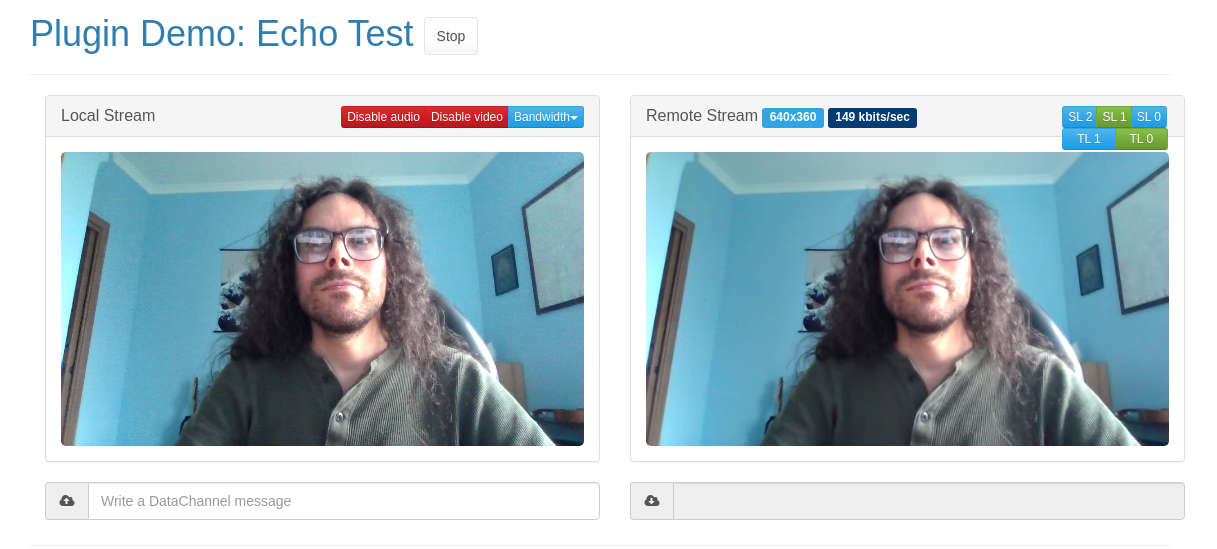
In this specific screenshot, I was playing with changing both substreams (rid=m in this case) and temporal layers (TL=0), which worked as expected. And if you’re wondering why it looks exactly like the VP9 simulcast+TL screenshot from before, well, it’s because it does! The UI is exactly the same in all cases, independently of the codec, so if they all work that’s actually good news. Just believe me when I tell you I’m not cheating!  (or test the PR yourself, unbeliever!).
(or test the PR yourself, unbeliever!).
This was already a quite satisfactory outcome of my experiments, but when I got to this point I started thinking: why not take this chance to try and get AV1/SVC working as well? If you recall, I anticipated how my previous experiments had only been partially successful, and I had been so burned by Dependency Descriptors that I had shelved the effort for the time being. Knowing the existing code was actually useful and working in the simulcast case (even though limited to temporal layers), it made sense to check if the same could be said for full SVC as well.
AV1+SVC=V: the Vs stand for “Veni, Vidi, Vici”!
Back when I started working on AV1/SVC, I worked a lot on the above mentioned Dependency Descriptor. As explained in the specification, that extension is indeed needed to get AV1/SVC working, as it provides all the information a decoder needs in order to be aware of the multiple layers that may be available (spatial and/or temporal), and more importantly the relationships and dependencies that intercur between all those layers (e.g., in terms of “what can I discard without breaking frames that depend on it and I still need?”).
I got on and on in the post about how much I hated the format the Dependency Descriptor came with, though. Rather than being a simple enough binary format, as you can usually find in most network specifications, the DD resembled much more closely what video codec engineers usually come up with, with variable length bitstreams and complex parsing procedures. Eventually, after a lot of sweat (and swears ) I got a parser ready, and confirmed it worked with multiple snapshots generated by Chrome when SVC was enabled.
Unfortunately, a working parser ended up not being enough when I tried using it with the EchoTest in AV1/SVC mode: the highest quality spatial layer was always visible, but any attempt to drop to a lower quality spatial layer would break the video, and the only way to get it back would be to switch to the highest quality layer again. At the time I suspected the cause was I was not rewriting the Dependency Descriptor content before relaying it to subscribers: in fact, the DD contains a section called “Active Decode Targets”, and it was my assumption that this section needed to be rewritten any time a spatial layer selection took place. I had become so annoyed with the format at that point, though, that I stopped right there.
This was the milestone I was starting from in my new experiments, and a trivial attempt to do exactly the same (simple layer dropping guided by the content of the DD) obviously didn’t work this time either. In another discussion, Philipp Hancke again made a useful suggestion, where he mentioned that marker bits played an important role in SVC. This was something I was partly aware of already, since I had implemented a similar marker bit processing in Janus for VP9/SVC, but for some reason it had never dawned on me until then that the same might need to be done for AV1/SVC too.
If you’re unfamiliar with the marker bit, it is indeed a bit that is part of the RTP header. It is a bit of a weird specimen, since it has different meanings and scopes in different contexts: in audio streams, for instance, you usually see it set to 1 when audio first starts flowing, or starts flowing after it had been idle for a while; for video streams, you usually see it set to 1 on the last packet addressing a specific frame, so right before the timestamp changes. When used in SVC, though, its usage becomes more complex than that, due to the fact that a single captured video frame (and so represented by a single RTP timestamp) actually contains multiple different frames, due to the spatial nature of the encoding: this means that dropping packets can actually end up dropping the marker bit it contained too, thus confusing the receiving endpoint. The snippet below, for instance, is a representation of the value the marker bit has in consecutive packets: each line shows, in order, the spatial and temporal layers detected in the packet (via DD), and after that the value of the marker bit, the sequence number and timestamp from the the RTP header.
[SVC] 0/2, m=0, seq=19073, ts= 9393030
[SVC] 1/2, m=0, seq=19074, ts= 9393030
[SVC] 2/2, m=0, seq=19075, ts= 9393030
[SVC] 2/2, m=1, seq=19076, ts= 9393030
[SVC] 0/1, m=0, seq=19077, ts= 9395910
[SVC] 1/1, m=0, seq=19078, ts= 9395910
[SVC] 2/1, m=0, seq=19079, ts= 9395910
[SVC] 2/1, m=0, seq=19080, ts= 9395910
[SVC] 2/1, m=1, seq=19081, ts= 9395910
[SVC] 0/2, m=0, seq=19082, ts= 9398790
[SVC] 1/2, m=0, seq=19083, ts= 9398790
[SVC] 1/2, m=0, seq=19084, ts= 9398790
[SVC] 2/2, m=0, seq=19085, ts= 9398790
[SVC] 2/2, m=0, seq=19086, ts= 9398790
[SVC] 2/2, m=0, seq=19087, ts= 9398790
[SVC] 2/2, m=1, seq=19088, ts= 9398790We can see three “frames” here, identified by timestamps 9393030, 9395910 and 9398790. Each of those frames, though, contain multiple layers (spatial and temporal), as evidenced by the first numbers we see on each line. This means that, if we drop spatial layer 2, the sequence we get is the following (where of course we’d fix sequence numbers so that they’re always monotonically increasing, before sending the packets to recipients):
[SVC] 0/2, m=0, seq=19073, ts= 9393030
[SVC] 1/2, m=0, seq=19074, ts= 9393030
[SVC] 0/1, m=0, seq=19077, ts= 9395910
[SVC] 1/1, m=0, seq=19078, ts= 9395910
[SVC] 0/2, m=0, seq=19082, ts= 9398790
[SVC] 1/2, m=0, seq=19083, ts= 9398790
[SVC] 1/2, m=0, seq=19084, ts= 9398790The end result of that is that we’re indeed only sending packets belonging to spatial layers 0 and 1, now, and timestamps change as frames go, but the marker bit is never set to 1, which causes the recipient not to know a frame is complete and so to never decode it.
The fix for that was to implement a similar solution to the one I already had in place for VP9. For VP9, we rely on the so-called “end-of-frame” bit (E) from the VP9 Payload Descriptor to figure out when a frame is complete: in that case, if a packet we receive has the E-bit set, and belongs to the spatial layer the recipient currently means to receive (e.g., 1 rather than 2), then we set the marker bit accordingly. In the Dependency Descriptor extension, a similar role to the “end-of-frame” bit is played by the end_of_frame property in one of the mandatory fields, which I already parsed correctly: as such, I modified the SVC SFU logic when using the DD to use end_of_frame exactly as I used the E-bit for VP9 and, voilà! That got AV1/SVC working too!
The screenshot below comes from the EchoTest demo where I forced SVC with three spatial layers and three temporal layers (svc=L3T3 in the query string) and AV1 as the coded to use (vcodec=av1):

As you can see, selecting spatial layer 1 now did work as it should have! In my case, all spatial layers had a lower resolution than the one I got using AV1 simulcast, but that may be ascribed to the fact that SVC encoding may not be as optimized, and so may be using more resources (CPU?) than it should. Nevertheless, what I cared about was being able to switch layers, and that worked! What a relief, especially considering it meant I would never have to rewrite the DD myself as I feared… maybe it was not such a bad format after all
What’s next?
We’re at a point where simulcast now works as expected for VP9 and AV1, and as a nice side effect it gave me the energy to also fix the broken AV1/SVC we had, which is now working too. This means that, if you’re using Janus, those are all options you’ll have available once we merge the PR: that’s great news!
That said, before merging I plan to do some cleaning up of the code: for AV1 simulcast specifically, for instance, the process is still a bit awkward for plugins, since they have to be aware of the fact different operations may need to be performed in sequence, depending on the codec. This isn’t much of a problem for our own plugins (we write them, so we know!), but it may be for those that implemented their own plugins, and may be caught by surprise by this, or by changes in the existing function signatures.
Besides, the plan is to now extend the same functionality to other plugins that use simulcast as well. In fact, as anticipated I limited all my experiments to the EchoTest due to its “perfect testbed” nature, but it’s clear that this new functionality will only really start becoming useful once it’s part of plugins people use everyday, like the VideoRoom SFU. The EchoTest always is a good confirmation of when things work, so I don’t anticipate problems, but still that’s an integration that will need to happen before we can know for sure.
That’s all, folks!
I hope you enjoyed reading this: spending time on new WebRTC features and functionality is always fun for me to both work on and then talk about, so I hope this report will intrigue and interest you enough to start digging in this yourself too. If you play with it in Janus, please do let us know, as we’d definitely appreciate the feedback!