
About a year or so ago, we talked about how we added support for new codecs to Janus, namely AV1 and H.265, and why that was an interesting foundation for more exciting things to come. AV1 in particular was a very interesting addition, since it’s a joint effort of several companies to write a powerful royalty free video codec, explicitly conceived to support Scalable Video Coding (SVC) out of the box, which is obviously a very appealing feature, especially in the context of WebRTC (e.g., for conferencing and broadcasting purposes).
At the time, while Chrome had started, thanks to the efforts from CosMo Software, to support AV1 in its WebRTC stack (which led to the Janus integration I mentioned above), there wasn’t any SVC support as of yet, for a couple of different reasons: first of all, the library used for encoding and decoding AV1 (libaom) didn’t really support it yet, and most importantly, the standardization process for how to deal with SVC features on the wire (RTP) was still going on. Recently, this has changed, and the WebRTC stack in Chrome now has, thanks again to the amazing contributions from the CosMo team, experimental support for SVC as well.
Inspired by this very interesting blog post by Sergio Garcia Murillo, which explains in detail how the whole thing works, I decided to start tinkering with this new exciting functionality as well. It took me some time, and long (frustrated) pauses, to get me to a point where it (kinda) started working as expected, and while there still is a lot to do (TLDR; we’re not really there yet), I thought I’d share some information on where we are right now anyway, hoping it might be helpful to other poor souls about to embark on the same journey. The code for all I’ll talk about here is in a pull request page on the Janus repository.
SVC? What’s that?
As anticipated, SVC stands for Scalable Video Coding, and in very few words is basically a technique that allows you to encode, in the same video streams, multiple different spatial and temporal layers, thus allowing you to provide, to interested recipients, multiple options of different qualities depending on their requirements or bandwidth availability.
A common source of confusion, for many people, is how this differs from simulcast, since it seems to do pretty much the same thing. The key difference is that, while when using simulcast you actually encode and send different resolutions of the same source material in different streams (and using different RTP SSRCs), in SVC all those different resolutions are actually “baked in” the same video stream, a bit like onion layers one on top of the other. The following images, which come from a presentation I did a couple of years ago at IIT-TC (slides available here) that I encourage you to watch if you want to learn more, try to summarize this key difference in a visual way, using an SFU-based scenario to explain how they can be used.

Simulcast 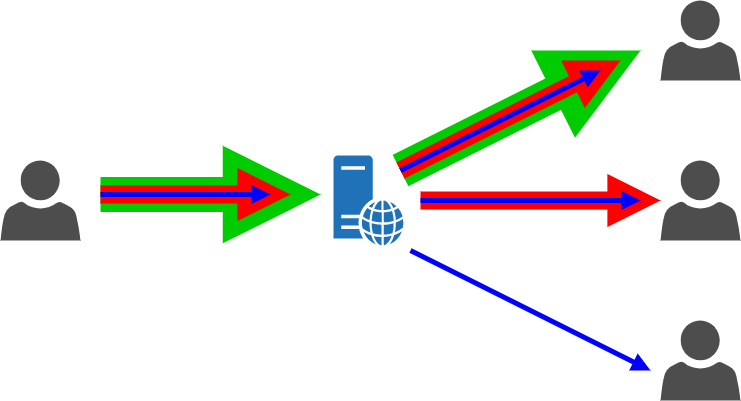
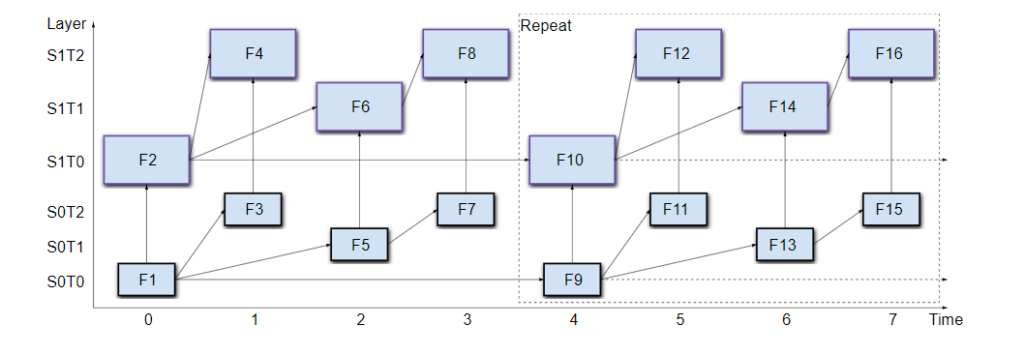
SVC
As you can see, a simulcast sender would need to encode the different options as separate streams: the SFU would then relay one or the other to the existing participants, depending on what is required or makes sense at any given time. When using SVC, instead, all the options are encoded in a single video stream: the SFU can then decide whether to relay the complete video stream (thus providing the best quality) to other participants, or strip some of the layers and only send part of the video stream data (thus reducing the quality using a lower resolution and/or a lower framerate).
Part of the confusion when it comes to simulcast vs. SVC in WebRTC comes from the fact that, out of the box, Chrome actually enables temporal layers scalability too when using, e.g., VP8 simulcasting, in order to allow servers to drop some packets to save some bandwidth at the expense of a lower framerate. This temporal scalability functionality is actually an SVC feature: simulcast itself only consists of encoding the different video resolutions in different streams.
Both simulcast and SVC have their pros and cons: simulcast is definitely simpler to implement and use, and can work with any video codec, but it does require more bandwidth, and may require more CPU since multiple encoders are involved; SVC is definitely harder to implement, and does require the video codec (and related encoders/decoders) to explicitly support it, but can provide a more robust experience, possibly saving some bandwidth and CPU usage in the process (even though SVC is definitely not lightweight on resources).
We already have some support for SVC in Janus, specifically for the VP9-SVC flavour that has been available as an experiment in Chrome for a while. As such, the fact that AV1-SVC is now available as part of the WebRTC stack is indeed an interesting opportunity, as it opens the door to a new alternative when it comes to writing even more robust video applications.
AV1-SVC and RTP
As all audio and video codecs, AV1 requires some packetization rules in order to be used in a protocol like RTP. This is typically needed because video frames often extend beyond a single RTP packet, and so rules must exist in order to figure out how the packet should be split, and what information should be added in order to be able to properly reconstruct the frame as it was originally encoded and sent. Unlike most other codecs, though, the RTP packetization rules for AV1 are not being standardized within the contect of the IETF, where it should (namely in the AVTCORE working group), but has been taken care of internally at the Alliance for Open Media (AOM) instead, which is there the standardization of the codec itself took place. This is an unusual process, which led to unusual results (more on that later), and will probably cause issues in the future: that said, an RTP payload format for AV1 now exists, and is specified in this document.
We had already looked at that specification a year ago, since we needed it when we first integrated AV1 in Janus: a knowledge of the RTP payload format was not strictly needed for Janus itself (since we only relay video packets, we won’t really need to know how media is packetized there), but was definitely needed in our post-processor code, which has to be able to depacketize media frames before they can be saved to a “traditional” container format (e.g., MP4). What we hadn’t looked at yet, though, was how this new RTP packetization may impact, or be impacted by, the SVC features, when enabled.
SVC functionality for AV1 in RTP is described in an Appendix of the very same document we linked above: the good news is that the RTP payload format doesn’t change when SVC is used; the bad news is that SVC relies on a brand new RTP extension to work, and it’s a f***ing nightmare!
A custom RTP extension is actually not a novel or scary thing: if you’re familiar enough with WebRTC, you may have heard of the Frame Marking RTP extension that Chrome (partially) implemented up to some time ago. The idea behind that extension was quite interesting: a generic RTP extension that could contain important info related to the video stream (e.g., whether the packet contains a keyframe, substream/layer the packet carries, etc.), independently of the video codec. This is an important functionality, as it frees intermediate components like an SFU to inspect the RTP payload to figure out that information, which is not only cumbersome and codec specific, but sometimes even impossible (e.g., when end-to-end encryption is used). As such, having the relevant information as part of a separate extension makes it much easier for an SFU to find the information it needs, e.g., to implement simulcast effectively. Unfortunately, the Frame Marking extension soon lost steam, as its specfication itself varies depending on which codec is in use, which makes it quite painful to implement and support properly.
This led AOM to design a brand new RTP extension instead, called “Dependency Descriptor”, to transport information related to the SVC properties of the video stream. The idea behind it was to write a generic extension that could be used by other SVC-compliant codecs as well. A noble intent, if the extension wasn’t such a frustrating specification (at least to poor old me). Sergio did an excellent job in explaining how the extension itself works in his blog post on AV1 chains, so I encourage you to refer to that if you want a more in-depth overview of the whole process, but in a nutshell, the extension works under the following assumptions:
- an SVC stream can reference one or more templates (which are listed in the specification), e.g., depending on which spatial/temporal layer is used, related decode chains, video resolutions of each, etc.;
- each RTP packet contains a Dependency Descriptor extension object, which may either contain a list of all the existing templates and their configuration (usually sent with keyframes), or just reference an existing template from that list (e.g., to indicate which spatial/temporal layer this packet belongs to).
This means that, as an SFU, you actually need to track all packets and keep a lot of state, rather than just relaying packets around based on some simpler rules instead, as all packets will reference something you received before, and so you must be prepared for it. This is a flexible approach (more SVC templates could be added in the future without touching the specification), but is already quite painful, as while keeping state is not that bug of an issue (you still need to keep some state even when using simulcast, for instance), the amount of state you need to keep for AV1-SVC, at least if you want to do things properly, is staggering. To make things worse, the extension was apparently designed by video codec engineers, which means it uses variable number of bits to carry information, making parsing or, God forbid, crafting an extension yourself an absolutely frustrating experience… which was probably unavoidable, as the template list needs to tell you, in a few bytes, all about the dependencies of an SVC stream like the one you can see below.
Isn’t this lovely?
As such, even though I was quite excited by AV1-SVC, it was with a heavy heart that I started digging into the specification a few months ago, to check what would be needed for a Janus integration.
First (painful) experiments in Janus
As anticipated, we already added support to Janus for AV1 as a codec a year ago, which meant that step was already taken care of. In order to support SVC as well, we first of all had to support the new above-mentioned Dependency Descriptor RTP extension, which meant being able to negotiate it in SDP, and of course somehow parse/process its contents.
Adding negotiation support for new RTP extensions in Janus is a relatively trivial process, since it typically means just adding a new define that references the new extension extmap, and the SDP utilities can use it automatically after that, if plugins/applications ask for it in SDP offers/answers. Parsing extensions can instead be a bit more effort, of course, as it usually depends on how complex the extension format is in the first place. As you may have guessed already, I hate the Dependency Descriptor format, so that took much more effort… 😀
There was actually another challenge I hadn’t anticipated, though, which emerged when I did my first experiments with the extension in Janus. More specifically, what I tried to do as a very first step was this:
- I added support for the new extension in the SDP utilities, to be able to negotiate it;
- I added core code to find the new extension in RTP packets when available, in order to copy the related data to the packet information (which is how extensions survive traversing plugins, in Janus);
- I configured the EchoTest plugin to negotiate the new extension, and relay its content back to the sender;
- I modified the EchoTest demo to optionally use the W3C APIs to enable SVC.
In an ideal world, this was supposed to have Chrome generate an AV1-SVC stream, send it to Janus together with the Dependency Descriptor RTP extension, receive the same information (media + extension) back from Janus, and display the content as a remote video stream as the EchoTest demo does.
To my surprise, this only worked in some cases and not others… more precisely, it seemed to work with SVC disabled or when using simple scalability modes like L1T2, but not when using any other scalability mode instead. Looking at the Wireshark traffic, everything seemed fine: the same exact extension content Chrome was sending to Janus, was being sent back as well, and yet video would not be displayed. Everything worked when enabling SVC but not negotiating the extension, which definitely seemed to point to something broken there.
At that point, I had already started working on some code to parse the extension. The code seemed to “barf” quite soon on some of the extension contents, while working fine for others. Specifically, it seemed that the extension data that was supposed to be sent along keyframes (and so the one containing all the templates) was the one the parser was failing on, but since I wasn’t sure whether it was my parser that was broken or something else, I wasn’t sure what the problem could be.
I then figured out that the problem was that the extension data seemed to be incomplete/broken for those keyframes, as for scalability modes like L3T3 (which contain A LOT of templates) the content seemed unnaturaly short, consisting of 8-9 bytes where I would have expected many more. A capture shared by Sergio in a working setup confirmed my suspicion, as in his case the extension was 95 bytes in that case! At that point, I assumed it was an issue in Chrome, so I opened a new issue, where they promptly explained to me I was actually an idiot (well, they didn’t say that, but I was).
The main problem was that, since the DD extension can be quite large (as the 95 bytes of Sergio’s capture confirmed), it relies on the so-called “two-byte header” RTP extensions, as the regular RTP extensions are capped to 16 bytes instead, and so would be to small to fit the data. Unfortunately, Janus didn’t have support for those, which explained why it wasn’t working: we were negotiating the extension, but not the a=extmap-allow-mixed attribute that is needed to signal support for two-byte header extensions, which resulted in Chrome still trying to send DD extensions, but turning them into one-byte header extensions instead, thus causing corrupt extensions to be sent out.
While there is something to fix in Chrome as well (it probably shouldn’t send DD, if two-byte header extensions are not supported), the issue had to be fixed in Janus. Adding support for two-byte header extension required a bit of a refactoring, especially in how we sent extensions ourselves, but as soon as that was done, the proper extension content would be sent by Chrome, and sent back by Janus as expected.

Habemus video! (but the road ahead is still long…)

This got video to work as well, which was definitely good news, since it confirmed we were negotiating and relaying the extension as required. Of course, in this case we were just forwarding the whole stream, that is all spatial and temporal layers, back and forth, and so not really taking advantage of the SVC encoding of the video: that said, it was an important first step, as it meant I could start focusing on the extension processing now, to try and use the SVC information for a smarter management of the stream.
Let’s try to mess with SVC…
Working on code to parse the extension is something I actually started months ago. I already explained more than once how complex the specification is (and how much I hate it), so I won’t repeat it again (or did I just do it?), but it was probably the unavailability of valid payloads to parse for testing that made it so much worse. In fact, even when I slowly progressed with the code, I didn’t have any way to validate if I was on right road or not.
As soon as I got the extension to work as expected, I finally had snippets of actual extension content I could use for the purpose, which sped up the process considerably. The output you see below is the result of the processing of the very first DD sent by Chrome, an extension containing the full list of templates for the L3T3 scalability mode configured in the web page.
[lminiero@lminiero tests]$ ./parse-dd dd-l3t3.hex
Opening file 'dd-l3t3.hex'...
Read 95 bytes (760 bits)
-- s=1, e=1, t=1, f=1
-- tdeps=1, adt=0, dtis=0, fdiffs=0, chains=0
-- -- tioff=0, dtcnt=9
-- -- Layers
-- -- -- [0] spatial=0, temporal=0
-- -- -- [1] spatial=0, temporal=0
-- -- -- [2] spatial=0, temporal=1
-- -- -- [3] spatial=0, temporal=2
-- -- -- [4] spatial=0, temporal=2
-- -- -- [5] spatial=1, temporal=0
-- -- -- [6] spatial=1, temporal=0
-- -- -- [7] spatial=1, temporal=1
-- -- -- [8] spatial=1, temporal=2
-- -- -- [9] spatial=1, temporal=2
-- -- -- [10] spatial=2, temporal=0
-- -- -- [11] spatial=2, temporal=0
-- -- -- [12] spatial=2, temporal=1
-- -- -- [13] spatial=2, temporal=2
-- -- -- [14] spatial=2, temporal=2
-- -- DTIs
-- -- -- [0][0] tdti=2
-- -- -- [0][1] tdti=2
-- -- -- [0][2] tdti=2
-- -- -- [0][3] tdti=3
-- -- -- [0][4] tdti=3
-- -- -- [0][5] tdti=3
-- -- -- [0][6] tdti=3
-- -- -- [0][7] tdti=3
-- -- -- [0][8] tdti=3
-- -- -- -- [0] dti=SSSRRRRRR
-- -- -- [1][0] tdti=2
-- -- -- [1][1] tdti=2
-- -- -- [1][2] tdti=2
-- -- -- [1][3] tdti=2
-- -- -- [1][4] tdti=2
-- -- -- [1][5] tdti=2
-- -- -- [1][6] tdti=2
-- -- -- [1][7] tdti=2
-- -- -- [1][8] tdti=2
-- -- -- -- [1] dti=SSSSSSSSS
-- -- -- [2][0] tdti=0
-- -- -- [2][1] tdti=1
-- -- -- [2][2] tdti=2
-- -- -- [2][3] tdti=0
-- -- -- [2][4] tdti=3
-- -- -- [2][5] tdti=3
-- -- -- [2][6] tdti=0
-- -- -- [2][7] tdti=3
-- -- -- [2][8] tdti=3
-- -- -- -- [2] dti=-DS-RR-RR
-- -- -- [3][0] tdti=0
-- -- -- [3][1] tdti=0
-- -- -- [3][2] tdti=1
-- -- -- [3][3] tdti=0
-- -- -- [3][4] tdti=0
-- -- -- [3][5] tdti=3
-- -- -- [3][6] tdti=0
-- -- -- [3][7] tdti=0
-- -- -- [3][8] tdti=3
-- -- -- -- [3] dti=--D--R--R
-- -- -- [4][0] tdti=0
-- -- -- [4][1] tdti=0
-- -- -- [4][2] tdti=1
-- -- -- [4][3] tdti=0
-- -- -- [4][4] tdti=0
-- -- -- [4][5] tdti=3
-- -- -- [4][6] tdti=0
-- -- -- [4][7] tdti=0
-- -- -- [4][8] tdti=3
-- -- -- -- [4] dti=--D--R--R
-- -- -- [5][0] tdti=0
-- -- -- [5][1] tdti=0
-- -- -- [5][2] tdti=0
-- -- -- [5][3] tdti=2
-- -- -- [5][4] tdti=2
-- -- -- [5][5] tdti=2
-- -- -- [5][6] tdti=3
-- -- -- [5][7] tdti=3
-- -- -- [5][8] tdti=3
-- -- -- -- [5] dti=---SSSRRR
-- -- -- [6][0] tdti=0
-- -- -- [6][1] tdti=0
-- -- -- [6][2] tdti=0
-- -- -- [6][3] tdti=2
-- -- -- [6][4] tdti=2
-- -- -- [6][5] tdti=2
-- -- -- [6][6] tdti=2
-- -- -- [6][7] tdti=2
-- -- -- [6][8] tdti=2
-- -- -- -- [6] dti=---SSSSSS
-- -- -- [7][0] tdti=0
-- -- -- [7][1] tdti=0
-- -- -- [7][2] tdti=0
-- -- -- [7][3] tdti=0
-- -- -- [7][4] tdti=1
-- -- -- [7][5] tdti=2
-- -- -- [7][6] tdti=0
-- -- -- [7][7] tdti=3
-- -- -- [7][8] tdti=3
-- -- -- -- [7] dti=----DS-RR
-- -- -- [8][0] tdti=0
-- -- -- [8][1] tdti=0
-- -- -- [8][2] tdti=0
-- -- -- [8][3] tdti=0
-- -- -- [8][4] tdti=0
-- -- -- [8][5] tdti=1
-- -- -- [8][6] tdti=0
-- -- -- [8][7] tdti=0
-- -- -- [8][8] tdti=3
-- -- -- -- [8] dti=-----D--R
-- -- -- [9][0] tdti=0
-- -- -- [9][1] tdti=0
-- -- -- [9][2] tdti=0
-- -- -- [9][3] tdti=0
-- -- -- [9][4] tdti=0
-- -- -- [9][5] tdti=1
-- -- -- [9][6] tdti=0
-- -- -- [9][7] tdti=0
-- -- -- [9][8] tdti=3
-- -- -- -- [9] dti=-----D--R
-- -- -- [10][0] tdti=0
-- -- -- [10][1] tdti=0
-- -- -- [10][2] tdti=0
-- -- -- [10][3] tdti=0
-- -- -- [10][4] tdti=0
-- -- -- [10][5] tdti=0
-- -- -- [10][6] tdti=2
-- -- -- [10][7] tdti=2
-- -- -- [10][8] tdti=2
-- -- -- -- [10] dti=------SSS
-- -- -- [11][0] tdti=0
-- -- -- [11][1] tdti=0
-- -- -- [11][2] tdti=0
-- -- -- [11][3] tdti=0
-- -- -- [11][4] tdti=0
-- -- -- [11][5] tdti=0
-- -- -- [11][6] tdti=2
-- -- -- [11][7] tdti=2
-- -- -- [11][8] tdti=2
-- -- -- -- [11] dti=------SSS
-- -- -- [12][0] tdti=0
-- -- -- [12][1] tdti=0
-- -- -- [12][2] tdti=0
-- -- -- [12][3] tdti=0
-- -- -- [12][4] tdti=0
-- -- -- [12][5] tdti=0
-- -- -- [12][6] tdti=0
-- -- -- [12][7] tdti=1
-- -- -- [12][8] tdti=2
-- -- -- -- [12] dti=-------DS
-- -- -- [13][0] tdti=0
-- -- -- [13][1] tdti=0
-- -- -- [13][2] tdti=0
-- -- -- [13][3] tdti=0
-- -- -- [13][4] tdti=0
-- -- -- [13][5] tdti=0
-- -- -- [13][6] tdti=0
-- -- -- [13][7] tdti=0
-- -- -- [13][8] tdti=1
-- -- -- -- [13] dti=--------D
-- -- -- [14][0] tdti=0
-- -- -- [14][1] tdti=0
-- -- -- [14][2] tdti=0
-- -- -- [14][3] tdti=0
-- -- -- [14][4] tdti=0
-- -- -- [14][5] tdti=0
-- -- -- [14][6] tdti=0
-- -- -- [14][7] tdti=0
-- -- -- [14][8] tdti=1
-- -- -- -- [14] dti=--------D
-- -- FDiffs
-- -- -- [0][0] 12
-- -- -- -- [0] --> 1
-- -- -- -- [1] --> 0
-- -- -- [2][1] 6
-- -- -- -- [2] --> 1
-- -- -- [3][2] 3
-- -- -- -- [3] --> 1
-- -- -- [4][3] 3
-- -- -- -- [4] --> 1
-- -- -- [5][4] 12
-- -- -- [5][4] 1
-- -- -- -- [5] --> 2
-- -- -- [6][6] 1
-- -- -- -- [6] --> 1
-- -- -- [7][7] 6
-- -- -- [7][7] 1
-- -- -- -- [7] --> 2
-- -- -- [8][9] 3
-- -- -- [8][9] 1
-- -- -- -- [8] --> 2
-- -- -- [9][11] 3
-- -- -- [9][11] 1
-- -- -- -- [9] --> 2
-- -- -- [10][13] 12
-- -- -- [10][13] 1
-- -- -- -- [10] --> 2
-- -- -- [11][15] 1
-- -- -- -- [11] --> 1
-- -- -- [12][16] 6
-- -- -- [12][16] 1
-- -- -- -- [12] --> 2
-- -- -- [13][18] 3
-- -- -- [13][18] 1
-- -- -- -- [13] --> 2
-- -- -- [14][20] 3
-- -- -- [14][20] 1
-- -- -- -- [14] --> 2
-- -- -- FDiffs count=22
-- -- Chains
-- -- -- [0] dtpb=0
-- -- -- [1] dtpb=0
-- -- -- [2] dtpb=0
-- -- -- [3] dtpb=1
-- -- -- [4] dtpb=1
-- -- -- [5] dtpb=1
-- -- -- [6] dtpb=2
-- -- -- [7] dtpb=2
-- -- -- [8] dtpb=2
-- -- -- [0][0] tcfdiff=12
-- -- -- [0][1] tcfdiff=11
-- -- -- [0][2] tcfdiff=10
-- -- -- [1][0] tcfdiff=0
-- -- -- [1][1] tcfdiff=0
-- -- -- [1][2] tcfdiff=0
-- -- -- [2][0] tcfdiff=6
-- -- -- [2][1] tcfdiff=5
-- -- -- [2][2] tcfdiff=4
-- -- -- [3][0] tcfdiff=3
-- -- -- [3][1] tcfdiff=2
-- -- -- [3][2] tcfdiff=1
-- -- -- [4][0] tcfdiff=9
-- -- -- [4][1] tcfdiff=8
-- -- -- [4][2] tcfdiff=7
-- -- -- [5][0] tcfdiff=1
-- -- -- [5][1] tcfdiff=1
-- -- -- [5][2] tcfdiff=1
-- -- -- [6][0] tcfdiff=1
-- -- -- [6][1] tcfdiff=1
-- -- -- [6][2] tcfdiff=1
-- -- -- [7][0] tcfdiff=7
-- -- -- [7][1] tcfdiff=6
-- -- -- [7][2] tcfdiff=5
-- -- -- [8][0] tcfdiff=4
-- -- -- [8][1] tcfdiff=3
-- -- -- [8][2] tcfdiff=2
-- -- -- [9][0] tcfdiff=10
-- -- -- [9][1] tcfdiff=9
-- -- -- [9][2] tcfdiff=8
-- -- -- [10][0] tcfdiff=2
-- -- -- [10][1] tcfdiff=1
-- -- -- [10][2] tcfdiff=1
-- -- -- [11][0] tcfdiff=2
-- -- -- [11][1] tcfdiff=1
-- -- -- [11][2] tcfdiff=1
-- -- -- [12][0] tcfdiff=8
-- -- -- [12][1] tcfdiff=7
-- -- -- [12][2] tcfdiff=6
-- -- -- [13][0] tcfdiff=5
-- -- -- [13][1] tcfdiff=4
-- -- -- [13][2] tcfdiff=3
-- -- -- [14][0] tcfdiff=11
-- -- -- [14][1] tcfdiff=10
-- -- -- [14][2] tcfdiff=9
-- -- Decode target layers
-- -- -- [0] spatial=0, temporal=0
-- -- -- [1] spatial=0, temporal=1
-- -- -- [2] spatial=0, temporal=2
-- -- -- [3] spatial=1, temporal=0
-- -- -- [4] spatial=1, temporal=1
-- -- -- [5] spatial=1, temporal=2
-- -- -- [6] spatial=2, temporal=0
-- -- -- [7] spatial=2, temporal=1
-- -- -- [8] spatial=2, temporal=2
-- -- Resolutions
-- -- -- [0] w=80, h=45
-- -- -- [1] w=160, h=90
-- -- -- [2] w=320, h=180
-- -- Active_decode_targets_bitmask (1)
-- -- -- adtb=511
-- spatial=0, temporal=0 (tindex 1)
-- -- Resolution
-- -- -- 80x45
-- Padding=0
Bye!
Are you lost/scared already? You should be, because it’s a mess! But if you look at it closely, there is some interesting information all of you should be able to parse even without knowing much about the DD specification:
- we see there’s three spatial layers (0-2) and two temporal layers (0-2);
- we also see the video resolutions for the three spatial layers at the time the DD was sent (the resolutions are quite low because the stream just started, and we’re in the ramp-up phase);
- finally, we see this particular RTP packet contains data for the spatial layer 0 and temporal layer 0 (which we know because it references template index 1).
The content actually contains much more info than that, though, as it also gives details about chains, decode targets and stuff like that: if you check the section of the document that lists the settings related to the scalability mode we chose, you’ll find that’s exactly the info we received, meaning that now we (should) know all that even if never read the document at all.
Now, let’s try to parse the second DD extension we received instead:
[lminiero@lminiero tests]$ ./parse-dd dd-l3t3-2.hex
Opening file 'dd-l3t3-2.hex'...
Read 7 bytes (56 bits)
-- s=1, e=1, t=6, f=2
-- tdeps=0, adt=0, dtis=0, fdiffs=0, chains=1
Error! Invalid template ID
-- Padding=27
Bye!
What happened? Well, we just received a much smaller packet which mostly only contains a reference to the big chunk we saw before. Since this application, as it is, is lacking the state from that previous message, it sees a reference to a template 6 that it knows nothing about, and so can’t do anything about it. This reinforces the statement I made before on the importance of keeping state, when using the DD extension: without state, it’s completely useless.
If we pass both the first and second extension to the parser (which allows it to keep some state, if possible) and snip the output from the first packet for brevity, we get something like this instead:
[lminiero@lminiero tests]$ ./parse-dd dd-l3t3.hex dd-l3t3-2.hex
Opening file 'dd-l3t3.hex'...
Read 95 bytes (760 bits)
-- s=1, e=1, t=1, f=1
-- tdeps=1, adt=0, dtis=0, fdiffs=0, chains=0
-- -- tioff=0, dtcnt=9
[..]
[..]
-- Padding=0
Opening file 'dd-l3t3-2.hex'...
Read 7 bytes (56 bits)
-- s=1, e=1, t=6, f=2
-- tdeps=0, adt=0, dtis=0, fdiffs=0, chains=1
-- spatial=1, temporal=0 (tindex 6)
-- -- Frame Chains
-- -- -- [0] fcfdiff=1
-- -- -- [1] fcfdiff=0
-- -- -- [2] fcfdiff=0
-- Padding=3
Bye!So, now that we know what template 6 means, we know the packet is related to spatial layer 1 and temporal layer 0. As explained above, we also know much more than that if we really look at the other data (e.g., in terms of decode dependencies), but for the sake of simplicity let’s just focus on the obvious information.
This gave me enough to try a very simple and naive implementation in Janus, that is, a Dependency Descriptor parser, some basic state management, and even simpler rules for deciding whether to relay a packet or not depending on the info that is available. As I often do, I used the EchoTest for job, which meant doing the following:
- adding a new struct to keep some basic state (at the moment, only the mapping between a template index and the related spatial/temporal layer)
- adding some code to process incoming DD extensions, to populate/update our state;
- adding APIs to the EchoTest plugin to indicate which spatial/temporal layers to send back (default=all);
- adding basic code to the RTP handler in the EchoTest plugin to drop a packet if the spatial/temporal layer is higher than the one we’re interested in (and if so, patch the sequence number so that there are no holes).
This process is not that different from the one we already have for simulcast and VP9-SVC, so it didn’t take long. Of course, considering the amount of info a DD extension can actually carry, it’s a VERY naive implementation, since it currently ignores some metadata that could be useful to understand when you can or cannot safely switch up/down. That said, I still wanted to check whether or not this crude implementation could do “something”.
The end result was a bit underwhelming, as while this worked as expected when dropping temporal layers (I could see the video becoming more jerky when forcing lower temporal layers), video broke when dropping spatial layers instead, and only started working again when I aimed for the highest available spatial layer instead (thus relaying them all).
There may be different reasons for this, but my guess is that the main cause for that is the fact we’re not updating the Active Decode Targets in the outgoing DD extension when we take the decision to drop some spatial layers. This piece of information tells the decoder which layers it should expect: I assumed that dropping some higher layers (e.g., spatial layer 2) while keeping the ADT intact (thus still listing that layer as well) would simply result in a less optimized decoding process on the receiver, but apparently it causes the video to break entirely for some reason.
Another possible reason is related to the decode chains: while it would be intuitive to assume that all packets that reference spatial layer 2 depend on some packets related to lower spatial layers, there may be some frame dependencies where it’s the other way around instead. In that case, we’d find ourselves in a case where we’re dropping a packet that will actually be needed by other packets along the road, thus breaking the decoder. This will definitely require some deeper study of dependency chains as they’re advertised in the DD templates, something that I’ve neglected to do so far to focus on more fundamental aspects instead.
Nevertheless, whatever the reason, the outcome was only a partial success, but one that got me much closer to the target than I was just a few days ago.
What’s next?
Well, as you’ve probably realized, there’s a lot still missing… while negotiating and relaying the extension data works as expected, and we have a parser that seems to do its job, we are currently not doing much with the information we receive. Even in the very simple scenario I set up, dropping some temporal layers seems to work as expected, while dropping spatial layers causes video to break.
This means that more work will need to be poured into this effort before it’s actually usable. This means not only keeping a better state of information we currently ignore (e.g., chains), but also write new code to craft a DD extension ourselves, which will be needed to update the Active Decode Targets (which is very likely the reason why video stops working when some layers aren’t relayed). All matter for a “part 2” of this blog post!
That said, I’m already quite satisfied with the current status of the code, especially considering the complexity of this new specification. If you’re as excited about this and want to give it a try, or possibly contribute fixes and enhancements, as anticipated the whole code (with the exception of the test DD parser) is available as a pull request. Even though it probably won’t make much sense since there’s no new custom UI, you can also just test it as a user on our official demos, using the EchoTest demo:
https://janus-legacy.conf.meetecho.com/echotest.html?vcodec=av1&svc=L3T3where you can replace L3T3 with any of the supported scalability modes. Notice that, for this to work, you’ll need to enable two separate things in Chrome, namely the experimental web platform features (required to enable the SVC features of AV1):
chrome://flags/#enable-experimental-web-platform-featuresand the custom fields trial to add support for the Dependency Descriptor RTP extension:
--force-fieldtrials=WebRTC-DependencyDescriptorAdvertised/Enabled/You can verify Chrome is configured correctly by issuing a RTCRtpSender.getCapabilities('video') on the JavaScript console, which should list both the additional scalability modes for AV1 and the new extension:
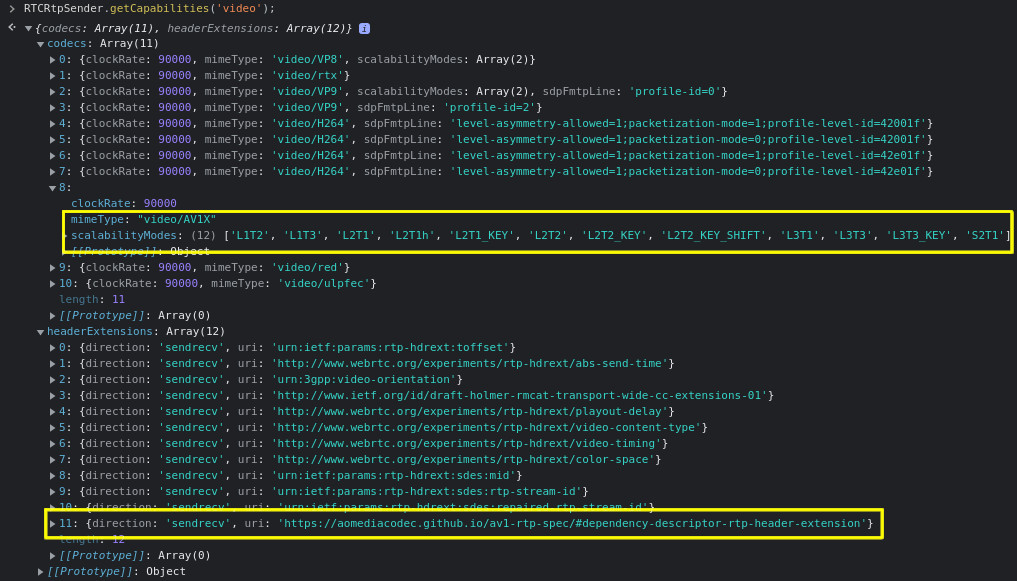
That’s all, folks!
I hope you enjoyed the read! While the technology is quite exciting, it has often been a frustrating experience for me, and so I hope that this summary will help other people to avoid some of the pitfalls I encountered. In case you’ve been playing with all this as well, I’d love some feedback!
Now it’s time for me to shut down the laptop for good, and possibly work on my tan… 😀 Enjoy your summer!