
I’m always interested in testing new codecs, especially when it comes to WebRTC. Some time ago, for instance, I talked about my experiments with AV1 and H.265, AV1-SVC or multiopus. As such, when a new codec called Lyra was announced that promised to give great audio in very low bitrates, I was definitely curious. In this blog post I’ll describe the steps I went through to get it to work in browsers and, most importantly, Janus.
What’s Lyra?
If you’re a fan of music as I am, the world “lyra” actually doesn’t bring a codec to mind at all, but a musical instrument instead: if your mythology knowledge is not too rusty, you may remember it’s the instrument Orpheus played, and played all through hell as well in order to try and bring his beloved Eurydice back (spoiler alert, he fails). This is not a course on Greek Mythology, though, so the “lyra” we’re talking about is something different.
More precisely, it’s a brand new codec designed by Google, and specifically conceived to use very low bitrates when doing speech compression. I won’t even try to describe how it works (the blog post Google engineers wrote to introduce it is a very good starting point, if you’re curious about that), but suffice it to say that it’s apparently so effective at incredibly low bitrates that, at the time it was still a thing, Google Duo actually used it in scenarios with very limited bandwidth. And best of all, it’s open source!
When talking of how low we’re talking when mentioning very low bitrates, apparently Lyra is conceived to provide good quality at ~3kbps: this is incredibly low (almost to the point where the RTP header can probably be seen as overhead!), especially when you think that Opus can get nearly there but only when doing narrowband (8khz), so at a lower quality than Lyra would provide. That said, the two codecs should actually be seen as complementary to each other, rather than “competitors”: again, Lyra mostly makes sense when the available bandwidth is very limited, which is where it can help still get decent audio despite the constraints. For higher quality audio at higher bitrates, Opus is still very much to be preferred.
That’s great! How do I use it?
Well, that’s the issue: at the moment, you can’t, or at least not out of the box. In fact, while Lyra may be integrated in some WebRTC stacks already (we mentioned Google Duo, for instance), it’s not implemented in libwebrtc at the time of writing, which means you can’t negotiate it in your “regular” PeerConnections as you can with, e.g., Opus or G.711.
These are interesting times, though, and it shouldn’t be a surprise to learn that this didn’t stop people from experimenting with it anyway within the context of a browser and JavaScript applications. More specifically, developers have started creating WebAssembly versions of the native Lyra library, so that they could encode and decode audio streams using Lyra in the browser itself. One excellent example is lyra-js, which is showcased in a really cool online demo that demonstrates the code in action. A similar demo is also available in lyra-webrtc, which uses Insertable Streams as a way to get access to the raw audio (we’ll get back to that in a minute!).
Both demos sounded really cool, and definitely sparked my interest, which is why I decided to roll up my sleeves and try to get something up and running of my own, possibly involving Janus as part of the process (because why not!).
L16 and Insertable Streams walk into a bar…
So, how do you use Lyra in a PeerConnection (maybe to send audio to Janus) if the codec is not in the supported list? Well, as the above-mentioned lyra-webrtc demo showcases, there’s some sort of a workaround that involves two main blocks:
- the L16 “codec” and,
- Insertable Streams (which we did talk about already some time ago, even though in the context of end-to-end encryption).
If you’re unfamiliar with what L16 is, it’s basically a hidden “codec” that you can use in browsers, that’s actually not a codec at all: when enabled in a PeerConnection, the browser simply puts uncompressed audio samples in RTP packets, and expects the same from peers. This explains why I’ve put “codec” in quotes twice (three times now, actually), since it really isn’t a codec: it’s simply a way to signal the intention not to use a codec at all, but use uncompressed audio in the conversation. Clearly, the use for it in actual sessions is pretty much zero: uncompressed audio is very heavy bandwidth wise, and so would make for a terrible choice when used on an actual network. That said, the reason we need L16 is different: specifically, since we want to use the WASM version of Lyra, and encode audio packets ourselves, L16 ensures we can get access to the uncompressed audio, rather than some already encoded audio.
We’ll get to how we can actually get access to audio samples in a minute, but let’s first of all check how we can enable L16, to see what we can do with it. As it often happens with hidden “secrets” that are not officially supported in libwebrtc, you can enable the feature via the infamous SDP munging, that is by manipulating the SDP generated by the browser before passing it back: in this case, you simply need to add a new payload type with the L16 rtpmap (or replace a codec that exists already with L16), e.g., like this:
...
a=rtpmap:103 L16/16000
...L16 can be used at different sampling rates, and can be mono/stereo too, but for the sake of simplicity (also considering it’s the only one we’ll need at this stage), let’s stick to 16000 as a sampling rate. When negotiated as the main codec to use for audio by both peers, the end result will be that, as anticipated, RTP packets won’t contain encoded frames, but uncompressed audio instead, which as we’ll see in a minute will be quite important in order to be able to use Lyra in JavaScript.
Of course, for this to work with Janus, I had to first of all make sure Janus supported L16 as part of its internal negotiation process. Without going too much in detail, this is exactly what I did a few days ago, and published as a pull request on the official Janus repo. If you want to test what I’ll talk about in this post in practice, you’ll need to make sure you’re running a version of Janus that does support L16, which means either compiling that pull request, or wait for it to be merged upstream.
Getting the browser to generate uncompressed audio frames, though, is only half the picture. In fact, the way we actually do get access to the audio samples is different, and is where Insertable Streams (IS) come into play. As anticipated before, we did actually talk about IS already in the past: in that blog post, it was to introduce a mechanism for implementing end-to-end encryption across media servers (e.g., via SFrame), but that’s not the only thing you can do with IS. In fact, they simply provide us with ways to transform the payload of RTP packets before actually send them, and while encrypting them is an option, there’s much more you can do with them: adding metadata is an example (e.g., sending MIDI along audio), but any manipulation of the frame is an option too. How it works in general, and where IS sit in a media processing chain, is summarized in the diagram below.
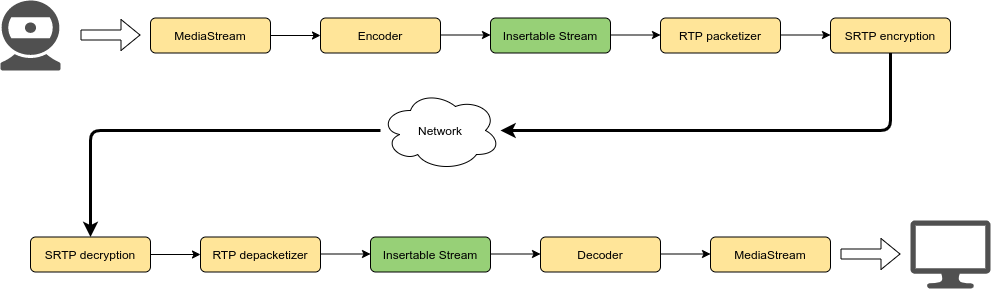
What is important in the diagram above is that both Encoder and Decoder are actually empty components if we use L16. In fact, when L16 is used, the browser won’t encode the audio frames at all, but will assume it has to send uncompressed audio frames in RTP instead. This means that, using Insertable Streams, we can add a transform function that takes care of both encoding and decoding ourselves, e.g., using the Lyra WASM version in JavaScript.
As such, the workflow on the way out will like the following:
- the browser will capture audio from a microphone;
- audio won’t be encoded (we’re using L16) but only resampled (e.g., 16000);
- our transform function in Insertable Streams will receive a buffer that contains uncompressed audio;
- we can encode this buffer ourselves, using
lyra-js; - we can return the encoded buffer as part of the IS transform function process;
- the Lyra-encoded frame will become the payload sent in RTP packets.
On the way in, the inverse will happen:
- the browser will receive an RTP packet with a Lyra payload (but with the L16 payload type);
- our transform function will receive a buffer that contains a Lyra-encoded buffer;
- we can decode this buffer ourselfes, using
lyra-js; - we can return the decoded buffer (which will now be uncompressed audio);
- the browser will assume it’s L16 (it is) and just resample it;
- the successfully decoded audio is now rendered/played.
As you can see, our workaround obtained hacking together different technologies should do the trick, so we can test this in practice in a demo page to see if it really works!
Preparing a demo
As it often happens when I experiment with new things, I decided to work on a demo using the Janus EchoTest plugin. In fact, it’s the simplest way to negotiate custom functionality, and ensure that whatever is sent is also received back, which makes it the obvious choice to test if a Lyra packet we capture and encode ourselves is a Lyra packet we can also decode and render. This is why having access to a L16-compatible version of Janus was obviously important.
As we discussed in the previous section, this demo needed two fundamental features:
- first of all, it needed to negotiate L16 in the resulting PeerConnection;
- besides, it needed to take advantage of Insertable Streams to use the Lyra encoded manually.
Janus already ships a demo that uses Insertable Streams out of the box (called e2etest, since it was conceived to demonstrate a simple encryption mechanism), so that’s where I started from.
The first step, of course, was to prepare a demo that could use lyra-js in the first place, and this meant allowing janus.js to be loaded as a module, since lyra-js is a module as well. As already explained in the old blog post on Insertable Streams, this was quite trivial, since all I needed to do was adding an export line at the end of the file:
export { Janus };and then import it from the application script file:
import {Janus} from './janus.js';The next step was ensuring L16 would be negotiated, since we need uncompressed audio to encode it ourselves. As anticipated, this is something that you can activate with SDP munging, that is by explicitly manipulating the content of the SDP itself before you pass it to setLocalDescription or setRemoteDescription. This is relatively easy to do when using janus.js, since it exposes callbacks you can implement when you need any customization of the SDP done. The EchoTest plugin expects an offer from clients, which means the code to add Lyra could look like this:
echotest.createOffer(
{
[..]
customizeSdp: function(jsep) {
// We want L16 to be negotiated, so we munge the SDP
jsep.sdp = jsep.sdp.replace("a=rtpmap:103 ISAC/16000", "a=rtpmap:103 L16/16000");
},
[..]To keep it simple, I decided to simply replace an unused codec (ISAC in this case) with L16, which means the payload type for L16 (and our Lyra encoded-frames) would be 103. Besides, since I wanted L16 to be the codec that would actually be used in the conversation (instead of, let’s say, Opus), I also ensured that communication with the EchoTest plugin explicitly mentioned L16 as the codec to force:
let body = { audio: true };
// We force L16 as a codec, so that it's negotiated
body["audiocodec"] = "l16";
echotest.send({ message: body, jsep: jsep });In fact, while the EchoTest plugin normally accepts the codec with the highest priority in the SDP, you can tell it to prefer a different codec instead, by explicitly naming it in the audiocodec property: by setting “l16” there, we know that’s what the EchoTest plugin (and so Janus) will negotiate for this session. To keep things simple and only focus on the audio part, compared to the “regular” EchoTest demo I decided not to negotiate video or datachannels at all instead.
Having dealt with L16, the next step was enabling Insertable Streams. As discussed before, I had some code for that already, so I basically just had to implement the transforms I wanted and replace the ones that existed. Getting janus.js to enable Insertable Streams is acually quite trivial, since all you need to do is specify, when you do a createOffer or createAnswer, the transforms you’ll use for media. This means that, if we extend the createOffer we saw before, this is what it could look like:
echotest.createOffer(
{
// We want bidirectional audio, and since we want to use
// Insertable Streams as well to take care of Lyra, we
// specify the transform functions to use for audio
tracks: [
{ type: 'audio', capture: true, recv: true,
transforms: { sender: lyraEncodeTransform, receiver: lyraDecodeTransform } }
],
customizeSdp: function(jsep) {
// We want L16 to be negotiated, so we munge the SDP
jsep.sdp = jsep.sdp.replace("a=rtpmap:103 ISAC/16000", "a=rtpmap:103 L16/16000");
},Specifically, we’re using the new tracks array to specify what we’re interested in, in this case bidirectional audio: as part of the properties of this audio object, we can also specify the IS transport functions we want to implement on the way out (sender) and on the way in (receiver). The janus.js library will then in turn automatically configure the PeerConnection so that the transform functions are set accordingly.
As the name of the transform functions suggest, that’s where the actual Lyra encoding (lyraEncodeTransform) and decoding (lyraDecodeTransform) will happen, so let’s have a look at those too. Before we can do that, though, of course we first of all need to load lyra-js itself, which we can do like this:
import {isLyraReady, encodeWithLyra, decodeWithLyra} from "https://unpkg.com/lyra-codec/dist/lyra_bundle.js";This will give us access to three separate functions: the first one (isLyraReady) tells us when the library has actually finished loading, while the other two (encodeWithLyra and decodeWithLyra) are the functions that implement the actual encoding and decoding with Lyra (and exposed as JavaScript functions, since this is a WASM library). Of course, studying how those functions worked, e.g., in terms of method signatures, was a prerequisite to actually using them in our transforms.
When we have a look at how encodeWithLyra works, we can see it expects a Float32Array instance as the samples to encode, and the sampling rate of the samples as well. One thing that’s immediately apparent when you look at the function, is that it expects at least 20ms worth of samples: this may seem like not that big of a deal (20ms is pretty much the standard for RTP audio in most cases), but it turns out it actually is when you enable L16 as a codec. In fact, due to the uncompressed nature of L16 (which can generate large payloads), browsers actually default to a ptime of 10, which means they’ll only generate 10ms worth of audio samples for each RTP packet: since each time an RTP packet is about to be sent our transform is called, this means that our encoder wouldn’t have access to enough samples to work.
Unfortunately, buffering is not an option here, as our transform needs to always give the RTP packetizer data to work with. Luckily, though, the solution is rather simple, since all we need to do is tell the browser to use a ptime of 20 instead. This is again something we can do with SDP munging, but this time by modifying the answer we get back from Janus before the browser is aware of it. Since the browser only becomes aware of an SDP answer when handleRemoteJsep is called in janus.js, that’s where we can put our patch:
// When using L16, Chrome will use a ptime of 10ms automatically,
// but since the Lyra encoder needs chunks of 20ms, we munge
// the answer by forcing the ptime to be exactly that
jsep.sdp = jsep.sdp.replace("a=rtpmap:103 L16/16000",
"a=rtpmap:103 L16/16000\r\na=ptime:20");
echotest.handleRemoteJsep({ jsep: jsep });This fixes our first problem, and introduces the next. When uncompressed audio is available, our sender transform function gets access to it via an ArrayBuffer. This ArrayBuffer gives us access to the data in different ways (e.g., Uint8Array and Int16Array), but as we’ve seen before the encodeWithLyra function expects a Float32Array instance. Simply “casting” the buffer to Float32Array is not an option, here, as we need the array to contain enough samples (320, since we’re using a 16000 sampling rate), and an ArrayBuffer containing 640 bytes (as each sample in L16 is 16 bits, so two bytes) would become a Float32Array with 160 elements in it, which is incorrect. This means that we first of all need to interpret the ArrayBuffer as an array of 320 signed integers (Int16Array), and then we need to convert that to a Float32Array with 320 elements. It’s also important that the conversion process also transforms the range of data: in fact, while signed integers have a range of [-32768, 32767], we’ll want our Float32Array to have a [-1, 1] range instead, as that’s how the lyra-js encoder works.
As such, a first version of our transform function could look like this:
var lyraEncodeTransform = new TransformStream({
start() {
// Called on startup.
console.log("[Lyra encode transform] Startup");
},
transform(chunk, controller) {
// Encode the uncompressed audio (L16) with Lyra, so that
// the RTP packets contain Lyra frames instead
let samples = new Int16Array(chunk.data);
let buffer = Float32Array.from(samples).map(x=>x/0x8000);
let encoded = encodeWithLyra(buffer, 16000);
// Done
chunk.data = encoded.buffer;
controller.enqueue(chunk);
},
flush() {
// Called when the stream is about to be closed
console.log("[Lyra encode transform] Closing");
}
});As you can see, the transform function is quite simple, since first of all we access the chunk data as an Int16Array, then we transform it as discussed to a Float32Array, and finally we encode that with encodeWithLyra. The encoded buffer we then set as the new chunk data that we queue back into the controller, which means that the RTP packets that will be sent on the wire will actually have the encoded data as payload, and not the uncompressed frame that L16 gave us initially.
Now that the encoder is out of the way, let’s have a look at the decoder instead. Unlike encodeWithLyra, decodeWithLyra expects a Uint8Array instead to represent the encoded data, and the expected number of samples: the return value will instead be a Float32Array containing the decoded frame. This means that will have to basically implement, after the decoded has done its job, the reverse of what we did before, in order to ensure that the Float32Array we get back is transformed in the ArrayBuffer the browser will expect to be able to interpret it as L16. As such, the function can look like this:
var lyraDecodeTransform = new TransformStream({
start() {
// Called on startup.
console.log("[Lyra encode transform] Startup");
},
transform(chunk, controller) {
// Decode the Lyra audio to uncompressed audio (L16), so that
// we can play back the incoming Lyra stream
let encoded = new Uint8Array(chunk.data);
let decoded = decodeWithLyra(encoded, 16000, 320);
let samples = Int16Array.from(decoded.map(x => (x>0 ? x*0x7FFF : x*0x8000)));
// Done
chunk.data = samples.buffer;
controller.enqueue(chunk);
},
flush() {
// Called when the stream is about to be closed
console.log("[Lyra encode transform] Closing");
}
});Again, the process is relatively straightforward: we pass a Uint8Array representation of the ArrayBuffer to the decoder, which gives back a Float32Array instance in [-1, 1] range. Then, we transform that to an Int16Array instance with a 16-bit signed integer range, and set that as the buffer to queue back to the controller, since it will be in L16 format and so something the browser can digest for rendering purposes.
Now that all that’s done, let’s give it a try to see if it works!
Let there be <white noise>!
Some of you may have guessed it already by looking at the code, but while apparently correct, the code above won’t get us a working demo. As a matter of fact, the end result will be grating white noise!
The solution turned out to be quite easy (and silly), but initially I really couldn’t figure out the cause, until I chatted with my colleague Alessandro Toppi, who’s much (MUCH) more skilled at JavaScript development than I am, and I was afraid I was doing something wrong messing with all those array buffers. Considering the samples we were working with were of 16-bit, he suggested checking endianness, at which point I felt really stupid, since that’s exactly what I had dealt with just a couple of days before when adding L16 support to Janus and our recordings post-processor, and I simply had not considered the possibility it could be an issue here too. Needless to say, that was the exact problem!
If you’re not sure what I’m talking about, you may want to brush up on your Endianness knowledge, but long story (very) short, depending on your machine architecture, the ordering of bytes in data may be different on your machine than it is when you send data over the network. As a matter of fact, exactly to avoid this problem there’s something called “network order” that tells you exactly how you should format data when sending it on the wire, which is then “converted” to whatever ordering the machine expects using ad-hoc system calls (I know this is a gross simplification, but please do bear with me). The most common orderings you’ll find are big-endian (which is what network order uses) and little-endian (which is what you’ll find on most machines).

Now, the problem is that, when Insertable Streams are involved, the data we get access to is ready to be delivered, which means it’s in network order already. The lyra-js library, though, works with data in whatever order the machine is using: since that’s little-endian most of the times, the end result is that the data we feed to the encoder has samples written in the “wrong” way (as far as the library is concerned), and when data is decoded, the samples meant for the browser to render are written in the “wrong” way as well. Since in both cases this causes samples to look very different from how they originally were, the end result is, you guessed it, white noise.
That said, the fix was, as I mentioned, quite simple, since it just required me to handle endianness of the uncompressed samples manually, both before encoding and after decoding. A very simple and brutal way to do that when encoding is the following:
var lyraEncodeTransform = new TransformStream({
[..]
transform(chunk, controller) {
// Encode the uncompressed audio (L16) with Lyra, so that
// the RTP packets contain Lyra frames instead
let bytes = new Uint8Array(chunk.data);
let c;
for(let i=0; i<bytes.length/2; i++) {
c = bytes[i*2];
bytes[i*2] = bytes[(i*2) + 1];
bytes[(i*2) + 1] = c;
}
let samples = new Int16Array(chunk.data);
[..]Quite simply, before accessing the samples as an Int16Array as we did before, we fix endianness by just accessing the data as an Uint8Array first, and then swap the bytes in couples, since in this case endianness is affecting our 16-bit samples. This is a very rough attempt at doing what ntohs would normally do in a C application, and the end result is that, when we’ll convert the Int16Array to Float32Array for the encoder, the data will be in the order the library expects. Of course, since I’m doing it in JavaScript it’s probably not very efficient at all (it’s something you could do in a different WASM library, for instance, and I’m sure there’s better ways to do that), but for a simple test this is enough.
Likewise, we’ll need to do something similar for the decoder transform function, where the fix will need to be applied after the decoder has done its job instead, to turn the data in network order for the browser:
var lyraDecodeTransform = new TransformStream({
[..]
let decoded = decodeWithLyra(encoded, 16000, 320);
let samples = Int16Array.from(decoded.map(x => (x>0 ? x*0x7FFF : x*0x8000)));
// Done
chunk.data = samples.buffer;
let bytes = new Uint8Array(chunk.data);
let c;
for(let i=0; i<bytes.length/2; i++) {
c = bytes[i*2];
bytes[i*2] = bytes[(i*2) + 1];
bytes[(i*2) + 1] = c;
}
controller.enqueue(chunk);
[..]Again, very simple and very likely quite inefficient, but it did the trick for me: habemus audio!
Cool, cool, but how do I try it?
In order to allow you to test this yourself, I put all the code on a new repo on GitHub, called lyra-janus. Please refer to the instructions there on how to setup the environment and play with it. The repo is quite simple, as it mostly contains two things:
- a dumb web server that enables some specific CORS policies (required for WASM and ArrayBuffer);
- the custom demo page to use L16, Insertable Streams and
lyra-jstogether.
Of course, you’ll need a version of Janus that supports L16 to get it to work, so make sure you install that one too (i.e., installing the branch available in the related pull request).
Please notice that this is just a simple web page written for demo purposes, and so it shouldn’t really be used as is in a production environment. I mentioned how rough my endianness management is, for instance, which can very likely be improved with a custom WASM piece of code written for the purpose (Alessandro has definitely been bugging me about it  ). That said, it should “work”, and give you an idea of what Lyra can do with audio in a PeerConnection.
). That said, it should “work”, and give you an idea of what Lyra can do with audio in a PeerConnection.
How low is this very low bitrate?
Now that we have a running demo, let’s have a look at the impact on the resulting traffic. Specifically, let’s do a capture of the WebRTC PeerConnection RTP packets, to see what the unencrypted traffic looks like, and what it looks like when it’s encrypted instead. To do an unencrypted capture, we’ll simply use the feature the Janus Admin API ships out of the box.
Let’s have a look at the unencrypted dump first:

So far, so good: timestamps are increasing by 320 units, which is to be expected with a 16000 sampling rate (and because we’re using L16/16000 as far as the browser is concerned). What’s much more interesting is when we have a look at the payload of those RTP packets, though:

That’s just 8 bytes! 20ms of audio compressed in just 8 bytes! To give you an idea, the uncompressed audio was 640 bytes instead. If we consider 50 packets per second (since we’re assuming a ptime of 20), this means 8*50=400 bytes per second, so ~3kbps, which is in line with what the Lyra blog post says. That’s indeed a very low bitrate!
It gets even more interesting when we have a look at the RTP packet as a whole. Normally, an RTP header is just 12 bytes long, which is usually negligible, but in this case is already larger than the payload it wraps, which makes RTP itself almost a considerable overhead. In fact, it turns our 3kbps data into a 8kbps one: still quite low, but basically more than doubled what we started from.
In practice, though, it’s “worse” than that:
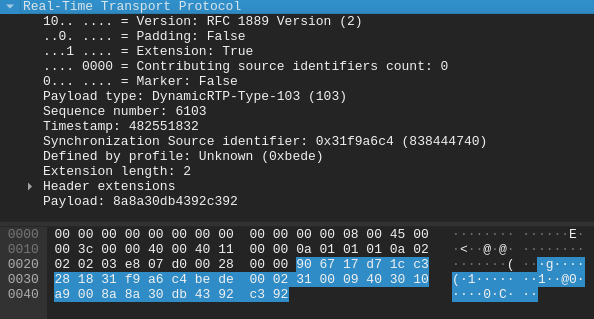
The actual RTP packet we captured is 32 bytes long, not 20! That’s because there’s additional RTP extensions in there (3, to be precise), that “beef” the packet up with 12 additional bytes. At 32 bytes per packet, we’re jumping from 3kbps to ~13kbps!
That said, this was the unencrypted packet: what happens when we have a look at the encrypted one instead?
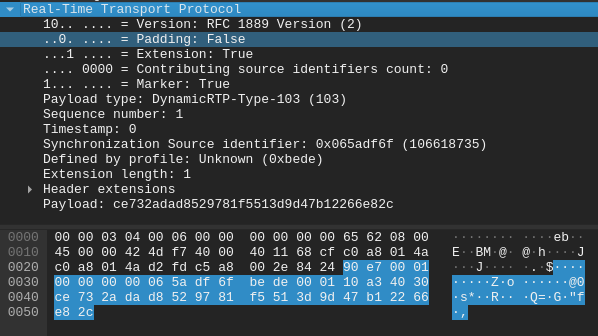
The packet gets even larger, 38 bytes to be precise: this is because SRTP encryption added even more bytes of its own, with the hash at the end of the packet. The initial 3kbps have become 15kbps!
Which means that, as low bitrate as Lyra is, there’s a ton of overhead that comes from the protocols that wrap and carry it around. As Tim Panton pointed out, in order to minimize the impact of such an overhead, it probably makes sense to use a much higher ptime when using Lyra, e.g., 100 rather than 20: in fact, while that would increase the overall latency (we’d only be sending our audio packets when we have at least 100ms worth of data ready), it would as a consequence greatly reduce the overhead of RTP and its extensions, since the payload of each RTP packet would now be 40 bytes rather than 8, and you’d only need to send 10 of those packets per second, so with way less bytes needed for RTP metadata as a whole.
That said, the irony of all this is that, as it currently is, the demo wouldn’t do much to help those in actual need of a low bandwidth codec. In fact, while it’s true that, RTP overhead notwithstanding, the encoded payload would be very small, the WASM library needed to actually encode it weighs 3.8 MB Of course there’s way around that, but it’s clear that an actual benefit will only come when Lyra as an encoder will be part of the stack you have access to in the first place, rather than having to download it first.
That’s all, folks!
As usual, I started with the intention of writing something short and sweet, and ended up writing yet another novel instead… that said, I hope you did appreciate this short trip in the world of Lyra nevertheless, and that you’ll have fun playing with the demo! It’s definitely an interesting novel technologies, which gave me the opportunity to also dip my toes in WASM codecs as well.
In case I don’t write anything else in the next few weeks, happy holidays to you all!