
Audio conversations that span to hundreds, if not thousands, of people have been quite the rage in the past few years. Podcasts are a good example of this success: there have never been so many as these days, and there’s a certain appeal to just listening to a conversation without the actual need for any visual aid or medium. It becomes even more interesting when you envision the possibility of more interactive conversations, where anyone from the audience can chime in at any time and share their thoughts. This has been at the basis of the success of platforms like Clubhouse, Reddit Talk or Twitter Spaces (which incidentally, in case you didn’t know, does use Janus for parts of its functionality; check Liubo’s talk from JanusCon a few years ago to learn more!), which are now usually referred to as “social audio” kind of applications.
So I thought, why not share a few words on how you could try and build a similar application using open source software, and Janus in particular? I did talk a bit about this when introducing our Virtual Event Platform at CommCon, a couple of years ago (it’s the platform we use to power remote participation at IETF and RIPE hybrid events), and more precisely when discussing our choices for the audio management, but some of the discussions in there are actually generic enough that they can be used to scale other kinds of audio application as well.
Please notice I’ll just be talking of the media part here: building a service like the ones I mentioned takes much more than that, of course (especially in terms of signalling, presence, mobile apps or engagement), but knowing how you could take care of audio might still be a good place to start building an open source replacement.
SFU or MCU?
There are different ways you can take care of the conversation part: in fact, no matter how large the audience is, good chances are that at any given time only a few people (a fraction of the actual participants) will be actively talking at the same time, meaning you can handle the conversation as a smaller scale “conference” of sorts, that you can then scale to a wider audience. Different people jumping in the conversation could be basically seen as dynamically changing the subset of active speakers in such a conference. Which brings to the first question: should you use an SFU or an MCU for that part?
I did make a presentation on the pros and cons of both appoaches at IIT-RTC some time ago, which you can watch here (or just check the slides). As you can guess, the anwer to that question is, as it often happens, “it depends”…  It’s often a tradeoff between computational resources on the server side and bandwidth requirements, or what you plan to do with the media. If, for instance, you’re going to mix media anyway because you’re going to broadcast the conversation via “traditional” means as well (e.g., to a CDN via RTMP, or as an Icecast stream), then it may make sense to mix it for the live session itself, which would make WebRTC broadcasting easier too (since there would always be a single audio stream to distribute). At the same time, though, live mixing can be CPU intensive, and since your MCU becomes the peer responsible for transcoding, quality may sometimes suffer as a result: as such using an SFU approach for the active participants and a different approach for the passive audience (for as long as they’re passive in the conversation) also works.
It’s often a tradeoff between computational resources on the server side and bandwidth requirements, or what you plan to do with the media. If, for instance, you’re going to mix media anyway because you’re going to broadcast the conversation via “traditional” means as well (e.g., to a CDN via RTMP, or as an Icecast stream), then it may make sense to mix it for the live session itself, which would make WebRTC broadcasting easier too (since there would always be a single audio stream to distribute). At the same time, though, live mixing can be CPU intensive, and since your MCU becomes the peer responsible for transcoding, quality may sometimes suffer as a result: as such using an SFU approach for the active participants and a different approach for the passive audience (for as long as they’re passive in the conversation) also works.
Let’s have a look at how both could work.
Using the AudioBridge to host the conversation
To start, let’s assume we want to use the MCU approach for our conversation. When using Janus, this would probably mean using the AudioBridge plugin for the purpose, since its main job is indeed mixing incoming audio streams, and providing each participant with an N-1 mix (they all receive a mix of all contributions except their own). The AudioBridge can work at different sampling rates (e.g., you may decide 16kHz is enough and you don’t really need 48kHz), and has interesting mixing functionality like stereo mixing (where if you wanted you could, for instance, “spatially” place different users in the stereo spectrum for a more live experience), depending on what you want to get out of it. It also allows you to play static audio files within the context of a room, which could be helpful if you want your show to have a music jingle, for instance, or when there’s some content to ingest and discuss about.
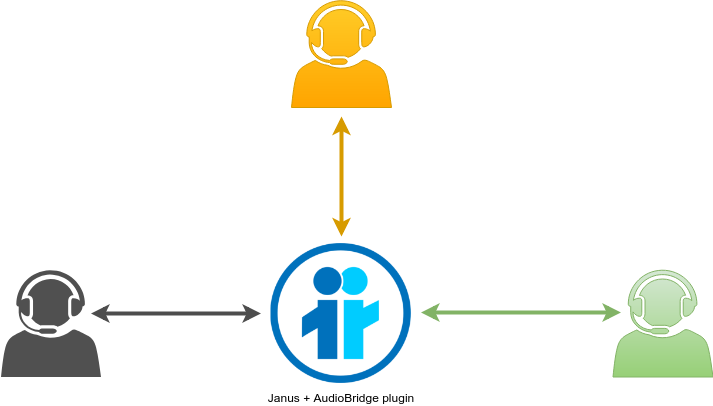
This works nicely for ensuring the active participants can talk to each other, but how can we ensure that a wide audience can benefit from this conversation as well? Just adding all passive attendees to that same conference room is a possibility, but one that would work quite badly, and scale poorly as well: in fact, the way the AudioBridge works right now any participant that is added to a conference room gets its own encoder and decoder. In fact, as we anticipated, the AudioBridge acts as an N-1 mixer, which means it must be prepared to craft and encode a separate mix for each participant: using the same mix for everyone would not work, as active speakers would hear themselves in the audio they get from the server. Considering the server cannot know in advance which speaker will become active in a conversation (and also considering the plugin allows for different configurations of the Opus encoder properties for different participants), this ends up with a different encoder context for each participant. While we have efforts to get rid of this constraint (e.g., in this pull request whose purpose is to allow a temporary “suspension” of the encoder for passive participants, and have them fallback on a shared mix instead), hooking passive users to the mixer itself would still not be that good of an idea, especially when scalability is a concern and a single server may not be enough to serve them all.
As such, there is indeed a need to separate the process of handling the active conversation and how it’s distributed to a wider audience. As it often happens when Janus is concerned, this is an area where the so-called RTP forwarders can help. As the name suggests, RTP forwarders basically provide with an easy way to dynamically “extract” media from Janus and make them available as an RTP stream to an external component, whether it is for processing or for scalability purposes. The AudioBridge plugin supports them too, and more precisely allows you to RTP-forward the live mix of a conference room to an external UDP address via plain (or SRTP-encrypted) RTP.
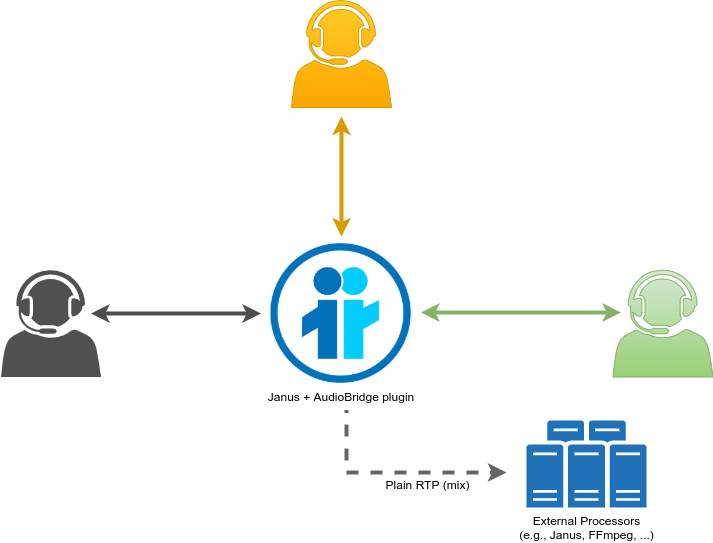
The moment we have access to a live mix as an RTP stream (which is very easy to distribute too, even using multicast where possible), there’s plenty of things we can do. We can pass it to the Streaming plugin on other Janus instances to have the stream distributed via WebRTC to interested subscribers, or we can transcode it to a different technology, like an Icecast server or a traditional CDN for broadcasting via, e.g., HLS. We could record the packets locally to have a recording of the conversation, or we could even pass this to a transcription service, to try and get a live transcription of the conversation going. Or you could do all this at once! It doesn’t really matter: what matters is that, once you have that stream, it’s up to you to decide how to handle it, and since it’s mixed already, the amount of people interested in it won’t weigh on the mixer itself, which is only responsible for the currently active participants instead.
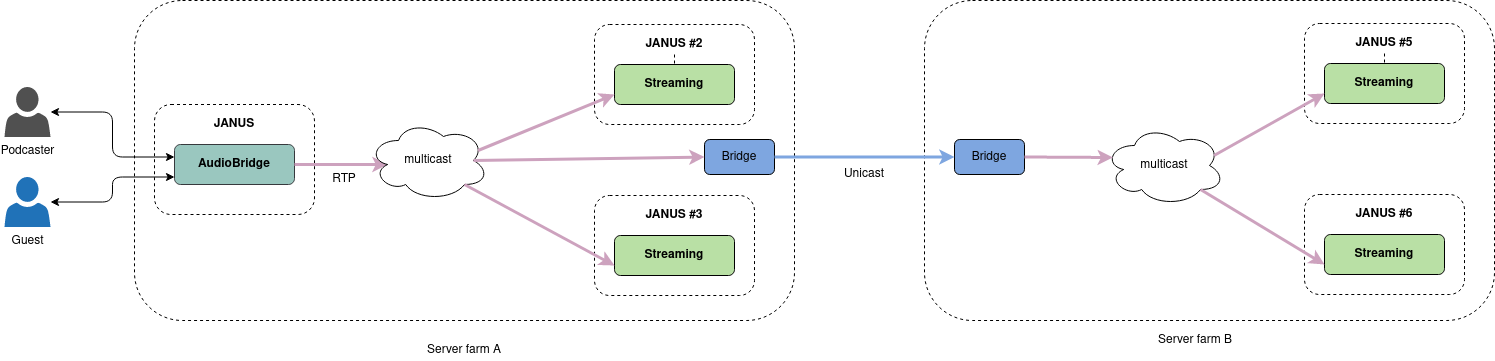
The pictures below shows how this could work with WebRTC and using the Streaming plugin, for instance, where a mix of a couple of active participants is then consumed by an audience of passive attendees via a different plugin, and possibly also different servers entirely, to widen the audience beyond the limits of a single instance. As briefly discussed before, the distribution could be even more complex, going through a tree-based distribution à-la SOLEIL, possibly even using multicast networks as a way to distribute the stream internally (even across multiple data centers).


Of course, we may still interested in ensuring that different people from the audience can be “promoted” to an active role in the conversation at any given time, whether it is just for a question or because they’re actually going to be actively discussing something with the other active speakers. Consider the disjointed nature of the live mix and how it’s distributed, this means envisioning ways to dynamically change the role of participants, so that a passive attendee currently receiving a static and receive-only mix can jump in the conference room and contribute someting that everything else will listen to.
A relatively simple way to do that is by simply allowing participants to dynamically create a new PeerConnection to the AudioBridge room when they need to speak (suspending the passive stream they were receiving so far), and tear it down to go back to the passive stream when they’re done. Considering we’re distributing the mix, there’s no need to update the distribution tree as different people take the floor, as the mixed stream always remains the same no matter who’s contributing to it. A simple visual representation of this approach is depicted below.
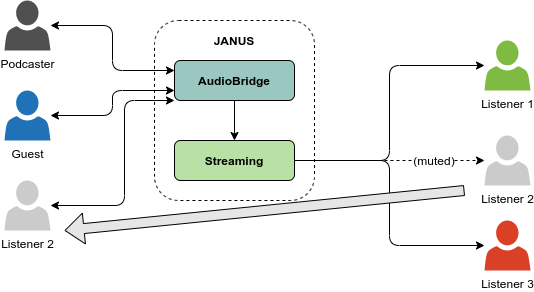
This is indeed the approach I described in the CommCon talk I referenced previously, as it is what we do in our Virtual Event Platform. In a virtual or hybrid event, different participants take turns in presenting, and others can at any time jump in to make questions or discuss things in a panel: considering there could be thousand of attendees in an event, such an approach makes it easy to only actively mix who’s supposed to be mixed right now, and then distribute the mix, whoever is in it, to all the other passive attendees via a more static broadcasting approach instead.
This has the advantage of keeping the delay very low for all participants involved, since whether a participant is active or not, WebRTC is always used both for contributing and receiving the mix (via the AudioBridge directly, or a Streaming mountpoint indirectly), thus allowing for a more interactive engagement. Of course, as discussed previously, the same mix could also be distributed via more traditional means instead, e.g., via HLS (low latency or not): in that case, there may be a bit more latency in the conversation (a participant may want to chime in on something they just heard but actually happened a few seconds ago in the live conversation), but depending on the target audience and the general expectations, it could still work.
An interesting by-product of choosing this MCU approach is that it could facilitate translation services as well, should they be needed. In fact, having the conversation mixed means you could use different rooms to, e.g., host the same conversation in different languages, where a live interpreter sits in one room and listens to the conversation there to talk in the other room and provide a translation there. Distributing the two separate rooms differently allows you to then providing localized content, where that may be required.

It’s of course more of an edge case, and possibly less needed in social audio applications like the ones we’re talking about (definitely more of a fit for traditional conferences), but it’s still a good thing to have, and one that we ourselves have used often in the live events we serve via our Virtual Event Platform for instance.
Using the VideoRoom to host the conversation
So far we’ve seen how you could use the AudioBridge to host the audio conversation, and how that can be scaled in different ways, taking into account the potential need to dynamically change the set of active speakers. All that implied we were using an MCU at the very source, meaning we’d mix participants for both active speakers (they’re connected to a mix, and receive an N-1 mix) and passive attendees (who all receive the same mix of currently active speakers). As we said in a previous section, though, that may not be how you want to approach the issue. Maybe you’d rather use an SFU instead, so that no server processing occurs on the audio streams, and active participants listen to exactly whatever the other speakers contributed. In that case, when using Janus the VideoRoom plugin is what you’d use for the job.
In fact, the VideoRoom plugin is what acts as an SFU in Janus, implementing a publish/subscribe approach that gives you enough flexibility to cover basically all scenarios that may need an SFU for the job. More precisely, the publish/subscribe nature of the plugin means that participants are free to decide whether they want to publish anything, and whether or not they want to subscribe to all available streams contributed by others, a subset of them, or even none at all. This makes it quite suitable for the conversation use case, as the picture below shows.

In the picture above, all participants are contributing something and are subscribed to all other active participants, which results in the multiple arrows you see. That said, though, in this case no mixing is involved, which means that every contribution could be seen as its own “broadcast”, which is something that can be used as far as scalability is concerned.
And scalability here is indeed the next problem to address, because exactly as with the AudioBridge before, this VideoRoom conversation can easily serve the needs of the conversation among the active speakers, but the whole idea is that this conversation should be accessible to a much wider audience instead, and again an audience that may have some attendees switch role to become active participants in a dynamic fashion.
Once more, this is something the RTP forwarders we introduced before can help with. The VideoRoom plugin, in fact, also supports them, even though in a different way than the AudioBridge does: where the AudioBridge is only capable of RTP-forwarding a single stream that is a mix of all active participants, the VideoRoom, being an SFU, can only RTP-forward the individual contributions separately. This means that, in a conversation among three people, you’d have to forward the three publisher streams separately, and handle them accordingly. The image below is a visual representation of how RTP forwarding actually works in the context of a VideoRoom, where the contribution a participant may be sending via WebRTC is relayed to other participants via WebRTC (SFU mode), but can also be forwarded as RTP to an external address for further processing.
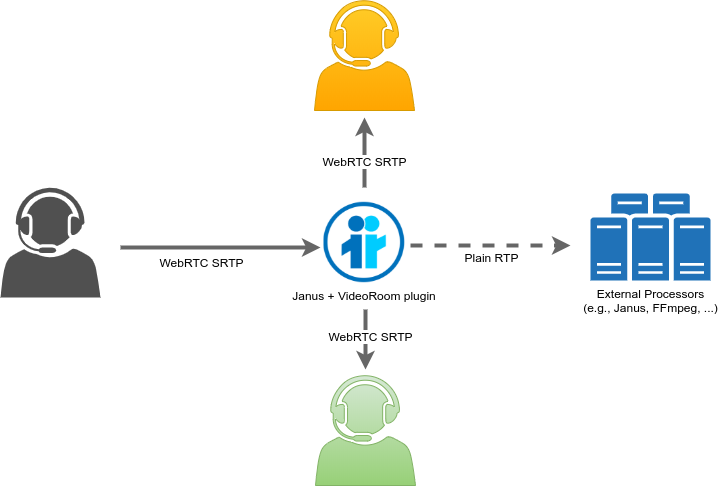
And again, just as with the AudioBridge before, there are different ways you could handle these incoming streams. You could decide to forward them as they are to other Janus instances, to basically cascade the distribution of ingested media and have the passive audience receive the streams separately via WebRTC and still in SFU mode (e.g., as discussed in this recent blog post on SFU cascading). Or you could decide to mix those streams instead, and then distribute them pretty much as we’ve seen before in the MCU scenario (where the stream was already available as a mix): mixing them would definitely be needed in case you wanted to distribute the conversation via traditional broadcast technologies, e.g., HLS, since that would require a single stream to broadcast. Again, recording the packets or feeding them to a transcription service are options too.
Using the SFU mode (and WebRTC) for the distribution part can be done in a similar way as how we’ve seen the distribution of the mixed stream in the previous section: using RTP forwarders we can decouple the stream ingested in the VideoRoom from how we distribute it, once more using one or more Janus instance to help with the task. The key difference is that now we’re not distributing a mix, but individual contributions, meaning that the same cascading process must occur for each of the active speakers, and so should be properly orchestrated the moment participants get in or out of an active role in the conversation.

It also means that, since each contribution is distributed separately, each contribution can also be seen as its own “broadcast”, and so scaled independently of the others. As a result, you’re not really required to have all active participants be connected to the same VideoRoom instance: any time a speaker becomes active, they can be connected to any VideoRoom instance that’s part of the cluster serving the scenario, and then it will be distributed and become “consumable” by any participant in the conversation, whether they’re active speaker or passive attendees. The image below, which again comes from the CommCon talk discussing our Virtual Event Platform choices, summarizes this in a visual way: in that presentation the media the image referred to was video (because in our platform we use mixed audio and SFU video), but it doesn’t really matter, as the same exact approach works for audio too.
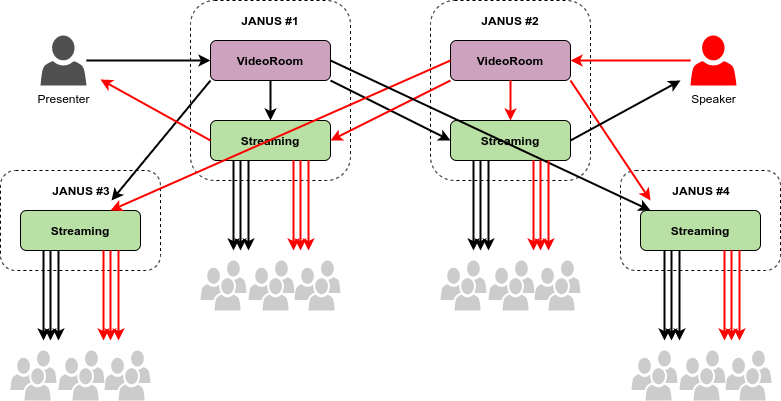
That said, while this approach is viable, it may not always be the best choice, especially considering that, with such an SFU mode and a potentially variable number of active speakers at any given time, you may end up having to distribute way too many streams to interested participants, and if numbers are high bandwidth may be a concern (if not for the server, maybe for clients).
In such a case, it may make more sense to envision an MCU mode for the distribution part instead, while keeping the SFU mode for active participation: as mentioned initially, this seems to be what Twitter itself is doing with Spaces, and the same thing could be happening inside Clubhouse and Reddit Talk as well. How to mix those streams is entirely up to you, and there are different options here: you could build your own mixer on top of open source frameworks, e.g., FFmpeg or GStreamer, leveraging RTP forwarders in the VideoRoom plugin to feed them with audio streams to feed, and then distribute the result any way you see fit (e.g., by using RTMP to send the mixed audio to a CDN); you could orchestrate Janus-to-Janus connections to have the VideoRoom publishers be added as participants in the AudioBridge, and then distribute the result as discussed before (a bit byzantine, but possible); you could leverage traditional MCUs like Asterisk (e.g., via ConfBridge) or FreeSWITCH by again orchestrating connections from the VideoRoom to there, and then use those as the root for the media to distribute; and so on and so forth.
Should you want to stick to an SFU approach, another interesting possibility would be to only distribute a limited number of streams, e.g., the 4 or 5 loudest speakers, via a static distribution, meaning the subscription channels themselves never changes as far as the audience is concerned, but only their audience does: this would reduce the bandwidth needed for subscribers, and keep the distribution tree at a minimum as well. This is something that you can do either with the “switching” functionality in both VideoRoom and Streaming plugin (where you can create a PeerConnection and then dynamically switch the source of the media that’s feeding it without a renegotiation, e.g., to stop listening to Alice’s audio and switch to Bob instead), or by orchestrating a dynamic usage of RTP forwarders where the same Streaming plugin mountpoint can be fed at different times by different active speakers (always one at a time, of course). Both require a good deal of orchestration, though, and so may be a bit harder to scale, which means it may make sense to implement some sort of dynamic switching at the plugin level: one thing we’re planning to work on sooner or later, for instance, is adding such a feature to the VideoRoom, where you can create a subscription to, e.g., N generic audio streams, which are dynamically switched internally depending on voice activity detection. Such a feature could be implemented via a meta-publisher of some sorts, which “looks” like a publisher as far as the API is concerned (RTP forwarders too, consequentially), but is actually fed by other actual publishers in the room in a dynamic and automated way without any need for a manual orchestration.
Again, what you decide to do with the media is entirely up to you, and what’s important is that RTP forwarders make it possible in an easy way, by providing a simple and basic intermediate technology (RTP in this case) as a way to make WebRTC streams available to possibly WebRTC-unaware applications to do what you need to do.
What else can you do?
There’s a lot that we haven’t touched here: as anticipated, I wanted to focus more on how you could get a conversation going and distribute it from a media perspective, and not much else, but even when just talking of media streams there’s a lot that could be said. I made a presentation on this at the Open Source World event last year, for which unfortunately no video is available: I did upload the slides for everyone to see, though.
We’ve talked about how you can take advantage of stereo audio for improving the quality of experience of listening to a conversation: it’s what Tim Panton does in his Distributed Future podcast and other projects, for instance, which works quite nicely. Using Janus, stereo is something you can either enforce in the AudioBridge (using spatial positioning in the mix), or do on your own using Web Audio on the client side when using the VideoRoom (where having access to separate SFU streams allows you to process them separately). Web Audio can also be of great help when processing audio streams in the first place, e.g., before they’re sent via WebRTC: this is where you could try to remove some background noise, for instance, or compress/equalize audio streams dynamically.
More in general, there are different extensions and “tools” that can help improve the quality of the audio streams on the wire, whether you’re using an MCU or an SFU. Opus itself gives a very good quality already, and can be configured to use higher bitrates when required. Different mechanisms for audio robustness to packet loss are available too (e.g., inband Opus FEC, or redundancy via RED), and DTX can be used to reduce traffic when not needed (e.g., when sending silence).
Again, there’s a lot of different things that can help you improve the overall experience the moment you dig deeper in optimizations and quality, but with this blog post I wanted to mostly highlight the different approaches you could use to scale an audio conversation in the first place.
That’s all, folks!
I hope you enjoyed this quick overview! While it did have a lot of points in common with a few presentations I made in the past, e.g., related to scalability, I feel it still provides some useful pointers to those interested in exploring the possibility of using WebRTC (and possibly Janus itself!) to replicate popular audio-only applications.