
As an audio mixer and MCU, the AudioBridge plugin is quite a popular plugin among Janus users and developers. It’s definitely a foundational component in our own Virtual Event Platform, for instance, where while we use an SFU approach for video streams, audio is always mixed instead.
I mentioned efforts around this plugin a few times already, like when I discussed how to use it to build social audio applications like Clubhouse or Twitter Spaces, or how it could be bridged (pun unintended!) to the SIP world. I also stressed out the importance of audio in the WebRTC world when introducing our support for redundancy via RED, which is currently not supported in the AudioBridge but hopefully (thanks to the changes discussed in this blog post) soon will.
As such, I decided to summarize a few of the efforts we’ve been carrying on with respect to the AudioBridge plugin. While some of the efforts have some intersections, they’re quite different and separate features, so I thought I’d briefly discuss them separately instead.
A brief recap on the AudioBridge plugin
If you’ve never used Janus or this plugin, and are unfamiliar with what it’s all about, you can refer to the previously mentioned blog posts as a good introduction, or even better to the official documentation. In a nutshell, though, as anticipated in the intro it’s basically an audio mixer, and as such allows you to implement, for instance, basic audio conferencing among different participants. Since audio is mixed and an N-1 approach is used, each participant uses a single PeerConnection to send their own contribution (if unmuted) and receive a mix of everyone else. A simple diagram is presented below.
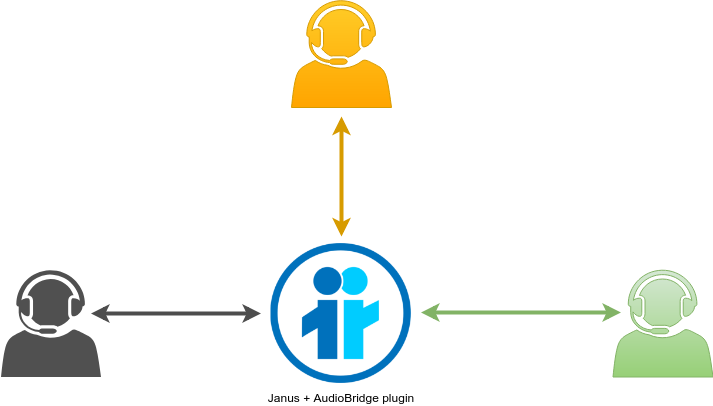
The plugin supports many features that allow it to be used in many more contexts than just basic audio conferencing, though. For instance, it supports the playback of static audio streams along actual participants, and allows for plain-RTP participants to join in the conversation as well (thus not limiting it to WebRTC only attendees). Most importantly, it allows for the real-time audio mix to be sent to an external component in real-time, which allows for many additional use cases (scalable distribution, live transcriptions, audio processing, etc.).
Within the context of this blog post, though, we can stick to the basics of the plugins, that is the ability to terminate audio connections in order to decode incoming RTP packets from multiple participants, mix them together at the right time, and then prepare different mixes for the different participants in the room (since it’s N-1, remember?). There’s quite enough there that can cause some headaches, at times, which is why we started working on some refactoring efforts to improve how the plugin works as a whole.
This includes:
- optional denoising of participants’ audio via RNNoise;
- a better jitter buffer for incoming RTP packets;
- reducing the CPU usage in presence of inactive participants.
As anticipated, all these features are actually functionally separate from each other, which is why I’ll discuss them in different sections, but you can see all those efforts as actually being different steps towards a better, and more reliable, AudioBridge implementation.
Denoising audio via RNNoise
RNNoise is a quite popular open source project, aimed at using deep learning to effectively implement noise suppression on audio samples. I’ll let you refer to the official sources for an in-depth explanation of how it works (I wouldn’t know where to start!), but for the sake of this section, let’s just say it’s really good at what it does: suppressing noise in audio streams. It’s available, for instance, as a plugin in the widespread OBS Studio broadcasting application, where it really helps cleaning audio a lot. A WASM implementation was also made available by Jitsi developers, in order to use its functionality directly at the source, in a browser, for real-time communication purposes.
Of course, I was intrigued to see if and how this could be used within the context of the AudioBridge, so in a server-side mixing component. Actually, some seeds had already been planted about three years ago, when one of the most active Janus users, Mirko Brankovic, contributed a pull request that tried to do exactly that, but was not merged eventually. It’s from there that I recently started studying a new potential integration, even though I soon found out I’d have to use a quite different approach.
In fact, Mirko’s patch worked on denoising the whole mix “after the fact”, rather than the individual participants before the mix. Considering how easily noisy and broken audio can “ruin” a mix, I felt trying to denoise the mix itself would not be enough of a band-aid, and that “cleaning up” the individual streams to mix before mixing them could lead to much better results, at the expense of course of a higher CPU usage (since you’d need to have N denoisers working at the same time, for N participants, rather than just one for the whole mix). Mirko’s patch also had a few other quirks that made it hard to use as it was, which is why I decided to try and refactor the integration from scratch instead.
The integration of RNNoise as an additional component in the audio processing workflow was actually a pretty straightforward process in itself. In fact, the AudioBridge plugin already had code devoted to handling incoming RTP packets, buffering them (more on this later!), and then decoding their payload (since the mixer needs to work on raw audio samples to do its job). As such, it was mostly a matter of adding RNNoise as an additional step to perform after decoding the payload, but before making the result available to the audio mixer. Of course, there were many other challenges related to this part that we’ll discuss in a second, but in general starting to work with RNNoise was very easy.
In fact, as a library RNNoise is very straightforward to use: you create an instance using rnnoise_create(), and perform denoising using rnnoise_process_frame(). Just as simple as that! The problem, though, is that RNNoise does make some assumptions on the format it expects audio samples to be. Namely, the documentation says:
It operates on RAW 16-bit (machine endian) mono PCM files sampled at 48 kHz
https://github.com/xiph/rnnoise
When you start digging, you find out it actually works on blocks of 480 samples, as floats. That’s indeed a problem, because of the different sampling rates the AudioBridge works at (8000, 16000, 24000, 48000), and that both mono and stereo are supported as well. Besides, even at 48khz, 480 samples are 10ms of audio, whereas conventionally RTP packets almost always contain 20ms worth of samples instead.
That forced me to be a bit creative with the way I passed samples to the denoiser. Focusing on mono streams at first, I noticed that if I iterated on the samples to do more rounds of denoising (e.g., twice when getting 960 48khz samples, 10+10), then denoising worked nicely both at 48000 and 24000 as sampling rates. For 8000 and 16000 as sampling rates, instead, trying to do the same would result in broken artifacts. A simple solution I came out with was a quick and dirty resampling: since denoising worked fine at 24000, why not quickly upsample 8000/16000 samples to 24000 before denoising, and downsampling the result back to 8000/16000 after the RNNoise call? That did do the trick indeed, at the expense of a very lightweight intermediate resampling step.

Getting stereo to work required me to think a bit outside the box again. In fact, I knew stereo audio would be interleaved when using Opus (meaning you have alternate samples for left and right channels in the stream). That said, I incorrectly assumed I could sequentially perform the denoising for the separate channels using the same RNNoise context, and that turned out not to be correct. Checking the source code for the above mentioned OBS RNNoise plugin I quickly figured out they’d create separate RNNoise instances for each audio channel, so as soon as I did the same in the AudioBridge plugin that fixed stereo audio too!
To test how well this would work in practice, I relied on some of the audio samples provided by the RNNoise project itself. To inject them as fake participants in an AudioBridge session, I modified my own Simple WHIP Server so that it would join the AudioBridge instead of the VideoRoom plugin (as it does by default), and then just used my Simple WHIP Client to stream those audio samples via WebRTC to a RNNoise-powered AudioBridge room. I guess there’s tons of other ways to do the same, but this was quick’n’dirty and effective enough for me! 
To conclude, I made the feature configurable, so that for each participant denoising can be enabled or disabled on the fly, depending on when/where it’s needed. The whole feature is optional, actually, since I made the RNNoise an optional, and not a mandatory, dependency for the AudioBridge plugin.
If you want to give this a try, you can refer to the pull request that contains the changes. The effort is basically complete, so it’s just there sitting and waiting for some more testing beyond my own. It will probably be merged soon, but not before the one implementing the changes described in the next section, which implement some deeper refactoring on how RTP packets are processed, and as a consequence would impact the RNNoise integration too.
Using libspeexdsp as a jitter buffer
While denoising is something that can help cleanup the incoming audio if the source is quite noisy, there’s another functionality that can have a considerable impact on audio quality, and that is a good jitter buffer. That’s double as important in a component like the AudioBridge, that terminates audio connections itself. In fact, in plugins that just shove packets around like the VideoRoom, you don’t really have to worry about buffering anything yourself, since the recipient will take care of any effort that may be required because of jitter or delay on incoming packets; the AudioBridge plugin doesn’t have that luxury, since it must decode audio packets itself, meaning it must ensure packets are in the right order, and possibly timed correctly before passing them to the mixer, independently of any jitter or delay that occurred on incoming RTP packets before they got to Janus.
The existing AudioBridge plugin does have a basic jitter buffer implementation, but it admittedly was never that great. It basically relies on prebuffering a specific number of packets (a configurable value) to act as a cushion to try and absorb fluctuations in the network: packets are decoded as soon as they arrive and then added to a buffer, and only once that buffer fills for the very first time it’s made available to the mixer, thus providing a more consistent stream for mixing purposes. This works fine most of the times, but is not very robust to situations where, for instance, the whole buffer ends up getting empty because of severe jitter or delays: in that case, the decoder starts working in what could be described as a “hand-to-mouth” implementation, which of course can cause choppy audio or audio artifacts.
To solve this issue, rather than trying to reinvent the wheel and build a brand new jitter buffer from scratch, we decided to simply just reuse an existing and reliable implementation instead to use in the AudioBridge. The choice for that fell on the jitter buffer implementation in libspeexdsp, a very popular and widespread implementation used in a ton of real-time communication applications, that implements many other useful features beyond the buffer itself.
Unlike the integration of RNNoise, though, integrating this new jitter buffer required some more effort. Not because libspeexdsp has a complex API (it’s actually quite easy to use!) but because it required some rethinking on our end of the workflow of packet processing, and a refactoring of all that as a process.
At the moment, the AudioBridge plugin has these three different pieces for every participant:
- the
incoming_rtp()callback, invoked by the Janus core loop thread, which passes incoming RTP packets from a participant to the AudioBridge plugin; this is where currently all processing, including decoding, happens; once decoded, a packet is added to a buffer for the mixer, which is only read once it’s full enough; - the
mixer_thread(), which is shared among all participants, and is where the mixer, at regular intervals, picks a packet from the queue of each individual participant, so that a mix can then be created; - the
participant_thread(), a separate thread for each participant, which takes care of taking the latest mix made available for that specific participant and encoding/sending it via WebRTC.
The presence of a new, more effective, jitter buffer forced us to rethink this flow a bit, especially considering decoding would now need to happen after the packet was added to the buffer, and not before. Since decoding was triggered by a new incoming RTP packet before (since decoding would always happen in place), this meant moving the decoding process to a different place, since we could not let a callback on a random RTP packet act as a trigger to decode a past packet that needs to be processed now. As such, we changed the code so that incoming_rtp() would simply put the packet in the jitter buffer instead, and moved all processing to the participant_thread(): this meant changing the processing in that thread a bit too, since while before we could just wait for outgoing packets to encode forever, now we’d have to handle checking the jitter buffer too for incoming packets.
The diagram below sketches what the new responsibilities of the participant thread are now (beyond encoding which is omitted for brevity). The incoming RTP callback does very little now, since all it does is put new RTP packets in the jitter buffer, while the mixer simply reads from a different queue but is otherwise left untouched.

This refactoring made for a much cleaner organization of the code and separation of responsibilities, besides making it easier to more effectively taking advantage of FEC, for instance (which wasn’t as effective the way we used it before). Besides, in the future it could allow for a potential integration of RED in the workflow too, since we could detect gaps in the packets flow from the buffer itself. The important part, though, was ensuring that the effort paid off, and from our internal tests it really seems like it did: we tested different participants with different levels of broken networks, and the end results sounded much better than it did on a “vanilla” AudioBridge instance using the old buffer. This was quite encouraring, even though we hope to make some more tests in the future as well.
That said, though, from an implementation perspective this refactoring also moved a lot of pieces around, which is why the RNNoise integration I discussed in the previous section will need to wait for this effort to be merged first: the RNNoise denoising, in fact, is part of the audio processing steps, which would be in a different place after the merge. A nice side effect of this, though, is that this would allow us to also take advantage of some other features libspeexdsp provides: that library also has a denoiser of its own, for instance, which means it could be used as a fallback in case denoising would be helpful to have but RNNoise support hasn’t been built-in.
This effort is also basically done, and is just sitting there waiting for more feedback from real users. In case you use the AudioBridge plugin, you’re definitely encouraged to test this, not only to catch potential regressions for us to fix in advance, but also because libspeexdsp will be a mandatory dependency for the plugin once merged, which means it could disrupt automated builds for those that aren’t aware. It’s currently available in two separate pull requests: one for the legacy branch (0.x) of Janus, and one for the multistream branch (1.x). Functionally they’re exactly the same, since the AudioBridge plugin doesn’t take advantage of the new multistream functionality in Janus, but since as a plugin it could be used along other plugins that do, it made sense to provide a way to test the integration in both branches.
Suspending and resuming participants
After talking of useful quality related features like denoising and jitter buffers, I thought I’d spend some words on a completely different functionality we’ve been also working on, specifically aimed at trying to reduce the load on the mixer in the presence of many participants in the same room.
Since the AudioBridge implements a mixer, it’s self evident that, the more participants there are, the more work it needs to do. It will need to decode more packets from more participants in real-time, it will have to mix more of them in the same mix without losing a beat, and will also need to encode a separate stream for each of the participants due to the fact that each participant may have a separate N-1 mix. You may think that simply muting participants would do the trick, but that only helps in part: it can help on the decoding side, since you may decide to simply not decode anything until a participant is unmuted, thus reducing a bit of CPU usage; the mixer itself is also smart enough to only mix unmuted participants. The real problem, though, are the separate encoders for each participant: even if a participant is muted, they’ll still have their own thread encoding the mix that has been prepared for them, even if it’s the same other participants may get. That’s indeed where the highest CPU usage resides, and where some work could be done.
The idea we came up with was suspending/resuming participants: in a nutshell, suspending a participant means “detaching” them from the mix (meaning we won’t process incoming RTP packets, and won’t send them any RTP packet either), but keeping the PeerConnection alive, so that the connection can quickly become active again when needed. This is a useful feature any time there’s users that are active somewhere else but want to stay in the room, or maybe in scenarios like our Virtual Event Platform where there may be a high turnaround of active/passive participants, and inactive participants would get the mix from a different place. The end result, anyway, is that a high number of inactive participants (ready to be activated) would not way on the CPU.
That said, while already potentially useful, this patch could be further extended to provide some additional functionality. A simple example that comes to mind, for instance, might be optionally providing inactive participants with a pre-encoded version of the mix, rather than having their own encoder do the job. This would make the patch useful not only for inactive participants, but also for recvonly participants, since in that case we’d just need a single encoder for all of them, and we could fan-out internally (a bit like the Streaming plugin does). Anyway, that may be something to think about after this patch lands in the mainstream version of the AudioBridge, and not before.
What’s next?
We covered quite a lot of different efforts related to the AudioBridge. As you’ve seen, all of them are pretty much in flux, right now, and are waiting for more feedback and testing before they can be merged: as such, the ideal next step would be for more people to actually give them a try and start using them, so that we may find potential areas of regression, or scenarios where they really don’t work as expected. We’ve been doing some extensive testing on the new jitter buffer stuff, and will probably use it in our products soon, but again some feedback from others beyond ourselves would be really great.
Apart from that, the AudioBridge is a really cool plugin to work with, and we often get new ideas on cool features we could add, or how we could make it even better than it really is. I already mentioned integrating the RED support we have in Janus, which could indeed increase the audio quality even more.
That’s all, folks!
Hope you appreciated this quick tour of what we’re doing on the AudioBridge! Again, if this is something you care about, make sure you give those PRs a try, and help us getting them merged upstream sooner rather than later.